 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale When Needed: Adaptive Neuron-level Mixed Precision Quantization Aware Training
May 24, 2026Deploying deep neural networks on resource-constrained 6G edge devices demands aggressive compression with minimal accuracy loss. Quantization-Aware Training (QAT) has emerged as a leading compression approach; however, existing mixed-precision methods typically operate at coarse layer- or channel-level granularity. These methods often rely on heuristic or search-based bit-allocation strategies, which may overlook fine-grained variability at the neuron level. We propose Neuron-Level Mixed-Precision QAT (NMP-QAT), where each neuron independently learns its own discrete precision during training. Starting from low-bit precision, NMP-QAT expands bit-width only when training signals demand it, via differentiable surrogates and straight-through estimators, while preserving a fully discrete inference graph. This adaptability extends to both weights and activations, reducing memory movement. Evaluated on telecom and non-telecom datasets across MLP and tabular foundation model architectures, NMP-QAT achieves superior compression-accuracy trade-offs over mixed-precision QAT baselines, making it well-suited for Green AI deployments at the network edge.
When to restart? Exploring escalating restarts on convergence
Mar 04, 2026Learning rate scheduling plays a critical role in the optimization of deep neural networks, directly influencing convergence speed, stability, and generalization. While existing schedulers such as cosine annealing, cyclical learning rates, and warm restarts have shown promise, they often rely on fixed or periodic triggers that are agnostic to the training dynamics, such as stagnation or convergence behavior. In this work, we propose a simple yet effective strategy, which we call Stochastic Gradient Descent with Escalating Restarts (SGD-ER). It adaptively increases the learning rate upon convergence. Our method monitors training progress and triggers restarts when stagnation is detected, linearly escalating the learning rate to escape sharp local minima and explore flatter regions of the loss landscape. We evaluate SGD-ER across CIFAR-10, CIFAR-100, and TinyImageNet on a range of architectures including ResNet-18/34/50, VGG-16, and DenseNet-101. Compared to standard schedulers, SGD-ER improves test accuracy by 0.5-4.5%, demonstrating the benefit of convergence-aware escalating restarts for better local optima.
Realistic Image-to-Image Machine Unlearning via Decoupling and Knowledge Retention
Feb 06, 2025



Machine Unlearning allows participants to remove their data from a trained machine learning model in order to preserve their privacy, and security. However, the machine unlearning literature for generative models is rather limited. The literature for image-to-image generative model (I2I model) considers minimizing the distance between Gaussian noise and the output of I2I model for forget samples as machine unlearning. However, we argue that the machine learning model performs fairly well on unseen data i.e., a retrained model will be able to catch generic patterns in the data and hence will not generate an output which is equivalent to Gaussian noise. In this paper, we consider that the model after unlearning should treat forget samples as out-of-distribution (OOD) data, i.e., the unlearned model should no longer recognize or encode the specific patterns found in the forget samples. To achieve this, we propose a framework which decouples the model parameters with gradient ascent, ensuring that forget samples are OOD for unlearned model with theoretical guarantee. We also provide $(\epsilon, \delta)$-unlearning guarantee for model updates with gradient ascent. The unlearned model is further fine-tuned on the remaining samples to maintain its performance. We also propose an attack model to ensure that the unlearned model has effectively removed the influence of forget samples. Extensive empirical evaluation on two large-scale datasets, ImageNet-1K and Places365 highlights the superiority of our approach. To show comparable performance with retrained model, we also show the comparison of a simple AutoEncoder on various baselines on CIFAR-10 dataset.
Unlearning Clients, Features and Samples in Vertical Federated Learning
Jan 23, 2025



Federated Learning (FL) has emerged as a prominent distributed learning paradigm. Within the scope of privacy preservation, information privacy regulations such as GDPR entitle users to request the removal (or unlearning) of their contribution from a service that is hosting the model. For this purpose, a server hosting an ML model must be able to unlearn certain information in cases such as copyright infringement or security issues that can make the model vulnerable or impact the performance of a service based on that model. While most unlearning approaches in FL focus on Horizontal FL (HFL), where clients share the feature space and the global model, Vertical FL (VFL) has received less attention from the research community. VFL involves clients (passive parties) sharing the sample space among them while not having access to the labels. In this paper, we explore unlearning in VFL from three perspectives: unlearning clients, unlearning features, and unlearning samples. To unlearn clients and features we introduce VFU-KD which is based on knowledge distillation (KD) while to unlearn samples, VFU-GA is introduced which is based on gradient ascent. To provide evidence of approximate unlearning, we utilize Membership Inference Attack (MIA) to audit the effectiveness of our unlearning approach. Our experiments across six tabular datasets and two image datasets demonstrate that VFU-KD and VFU-GA achieve performance comparable to or better than both retraining from scratch and the benchmark R2S method in many cases, with improvements of $(0-2\%)$. In the remaining cases, utility scores remain comparable, with a modest utility loss ranging from $1-5\%$. Unlike existing methods, VFU-KD and VFU-GA require no communication between active and passive parties during unlearning. However, they do require the active party to store the previously communicated embeddings.
Efficient Federated Unlearning under Plausible Deniability
Oct 13, 2024



Privacy regulations like the GDPR in Europe and the CCPA in the US allow users the right to remove their data ML applications. Machine unlearning addresses this by modifying the ML parameters in order to forget the influence of a specific data point on its weights. Recent literature has highlighted that the contribution from data point(s) can be forged with some other data points in the dataset with probability close to one. This allows a server to falsely claim unlearning without actually modifying the model's parameters. However, in distributed paradigms such as FL, where the server lacks access to the dataset and the number of clients are limited, claiming unlearning in such cases becomes a challenge. This paper introduces an efficient way to achieve federated unlearning, by employing a privacy model which allows the FL server to plausibly deny the client's participation in the training up to a certain extent. We demonstrate that the server can generate a Proof-of-Deniability, where each aggregated update can be associated with at least x number of client updates. This enables the server to plausibly deny a client's participation. However, in the event of frequent unlearning requests, the server is required to adopt an unlearning strategy and, accordingly, update its model parameters. We also perturb the client updates in a cluster in order to avoid inference from an honest but curious server. We show that the global model satisfies differential privacy after T number of communication rounds. The proposed methodology has been evaluated on multiple datasets in different privacy settings. The experimental results show that our framework achieves comparable utility while providing a significant reduction in terms of memory (30 times), as well as retraining time (1.6-500769 times). The source code for the paper is available.
Concept Drift Detection using Ensemble of Integrally Private Models
Jun 07, 2024



Deep neural networks (DNNs) are one of the most widely used machine learning algorithm. DNNs requires the training data to be available beforehand with true labels. This is not feasible for many real-world problems where data arrives in the streaming form and acquisition of true labels are scarce and expensive. In the literature, not much focus has been given to the privacy prospect of the streaming data, where data may change its distribution frequently. These concept drifts must be detected privately in order to avoid any disclosure risk from DNNs. Existing privacy models use concept drift detection schemes such ADWIN, KSWIN to detect the drifts. In this paper, we focus on the notion of integrally private DNNs to detect concept drifts. Integrally private DNNs are the models which recur frequently from different datasets. Based on this, we introduce an ensemble methodology which we call 'Integrally Private Drift Detection' (IPDD) method to detect concept drift from private models. Our IPDD method does not require labels to detect drift but assumes true labels are available once the drift has been detected. We have experimented with binary and multi-class synthetic and real-world data. Our experimental results show that our methodology can privately detect concept drift, has comparable utility (even better in some cases) with ADWIN and outperforms utility from different levels of differentially private models. The source code for the paper is available \hyperlink{https://github.com/Ayush-Umu/Concept-drift-detection-Using-Integrally-private-models}{here}.
Fair Differentially Private Federated Learning Framework
May 23, 2023Federated learning (FL) is a distributed machine learning strategy that enables participants to collaborate and train a shared model without sharing their individual datasets. Privacy and fairness are crucial considerations in FL. While FL promotes privacy by minimizing the amount of user data stored on central servers, it still poses privacy risks that need to be addressed. Industry standards such as differential privacy, secure multi-party computation, homomorphic encryption, and secure aggregation protocols are followed to ensure privacy in FL. Fairness is also a critical issue in FL, as models can inherit biases present in local datasets, leading to unfair predictions. Balancing privacy and fairness in FL is a challenge, as privacy requires protecting user data while fairness requires representative training data. This paper presents a "Fair Differentially Private Federated Learning Framework" that addresses the challenges of generating a fair global model without validation data and creating a globally private differential model. The framework employs clipping techniques for biased model updates and Gaussian mechanisms for differential privacy. The paper also reviews related works on privacy and fairness in FL, highlighting recent advancements and approaches to mitigate bias and ensure privacy. Achieving privacy and fairness in FL requires careful consideration of specific contexts and requirements, taking into account the latest developments in industry standards and techniques.
Literature Review of various Fuzzy Rule based Systems
Sep 15, 2022
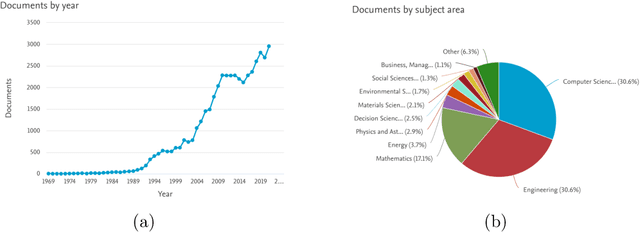
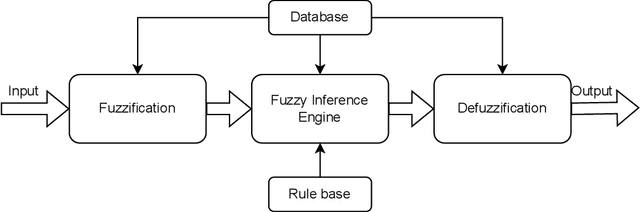
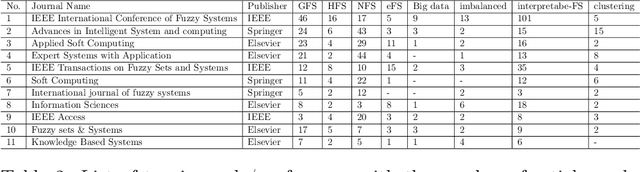
Fuzzy rule based systems (FRBSs) is a rule-based system which uses linguistic fuzzy variables as antecedents and consequent to represent the human understandable knowledge. They have been applied to various applications and areas throughout the literature. However, FRBSs suffers from many drawbacks such as uncertainty representation, high number of rules, interpretability loss, high computational time for learning etc. To overcome these issues with FRBSs, there exists many extentions of FRBSs. In this paper, we present an overview and literature review for various types and prominent areas of fuzzy systems (FRBSs) namely genetic fuzzy system (GFS), Hierarchical fuzzy system (HFS), neuro fuzzy system (NFS), evolving fuzzy system (eFS), FRBSs for big data, FRBSs for imbalanced data, interpretability in FRBSs and FRBSs which uses cluster centroids as fuzzy rule, during the years 2010-2021. GFS uses genetic/evolutionary approaches to improve the learning ability of FRBSs, HFS solve the curse of dimensionality for FRBSs, NFS improves approximation ability of FRBSs using neural networks and dynamic systems for streaming data is considered in eFS. FRBSs are seen as good solutions for big data and imbalanced data, in the recent years the interpretability in FRBSs has gained popularity due to high dimensional and big data and rules are initialized with cluster centroids to limit the number of rules in FRBSs. This paper also highlights important contributions, publication statistics and current trends in the field. The paper also addresses several open research areas which need further attention from the FRBSs research community.