 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Generalizability of Collaborative Dialogue Analysis with Multi-Feature Embeddings
Feb 09, 2023



Conflict prediction in communication is integral to the design of virtual agents that support successful teamwork by providing timely assistance. The aim of our research is to analyze discourse to predict collaboration success. Unfortunately, resource scarcity is a problem that teamwork researchers commonly face since it is hard to gather a large number of training examples. To alleviate this problem, this paper introduces a multi-feature embedding (MFeEmb) that improves the generalizability of conflict prediction models trained on dialogue sequences. MFeEmb leverages textual, structural, and semantic information from the dialogues by incorporating lexical, dialogue acts, and sentiment features. The use of dialogue acts and sentiment features reduces performance loss from natural distribution shifts caused mainly by changes in vocabulary. This paper demonstrates the performance of MFeEmb on domain adaptation problems in which the model is trained on discourse from one task domain and applied to predict team performance in a different domain. The generalizability of MFeEmb is quantified using the similarity measure proposed by Bontonou et al. (2021). Our results show that MFeEmb serves as an excellent domain-agnostic representation for meta-pretraining a few-shot model on collaborative multiparty dialogues.
Analyzing Team Performance with Embeddings from Multiparty Dialogues
Jan 23, 2021



Good communication is indubitably the foundation of effective teamwork. Over time teams develop their own communication styles and often exhibit entrainment, a conversational phenomena in which humans synchronize their linguistic choices. This paper examines the problem of predicting team performance from embeddings learned from multiparty dialogues such that teams with similar conflict scores lie close to one another in vector space. Embeddings were extracted from three types of features: 1) dialogue acts 2) sentiment polarity 3) syntactic entrainment. Although all of these features can be used to effectively predict team performance, their utility varies by the teamwork phase. We separate the dialogues of players playing a cooperative game into stages: 1) early (knowledge building) 2) middle (problem-solving) and 3) late (culmination). Unlike syntactic entrainment, both dialogue act and sentiment embeddings are effective for classifying team performance, even during the initial phase. This finding has potential ramifications for the development of conversational agents that facilitate teaming.
A Transfer Learning Approach for Dialogue Act Classification of GitHub Issue Comments
Nov 10, 2020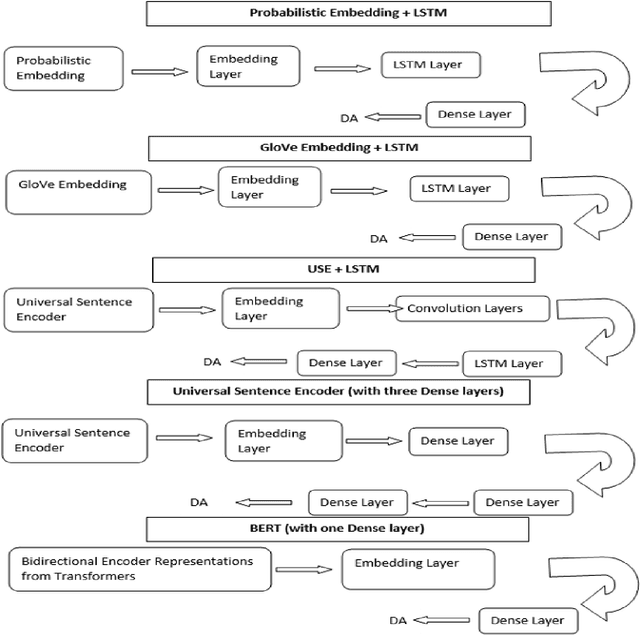
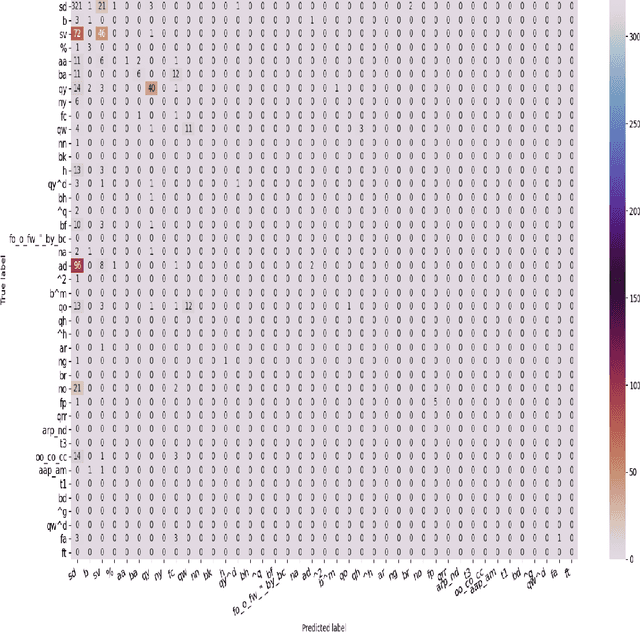

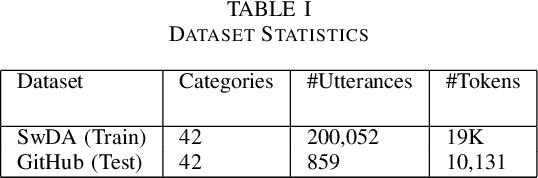
Social coding platforms, such as GitHub, serve as laboratories for studying collaborative problem solving in open source software development; a key feature is their ability to support issue reporting which is used by teams to discuss tasks and ideas. Analyzing the dialogue between team members, as expressed in issue comments, can yield important insights about the performance of virtual teams. This paper presents a transfer learning approach for performing dialogue act classification on issue comments. Since no large labeled corpus of GitHub issue comments exists, employing transfer learning enables us to leverage standard dialogue act datasets in combination with our own GitHub comment dataset. We compare the performance of several word and sentence level encoding models including Global Vectors for Word Representations (GloVe), Universal Sentence Encoder (USE), and Bidirectional Encoder Representations from Transformers (BERT). Being able to map the issue comments to dialogue acts is a useful stepping stone towards understanding cognitive team processes.