 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transfer Learning Approach for Dialogue Act Classification of GitHub Issue Comments
Paper and Code
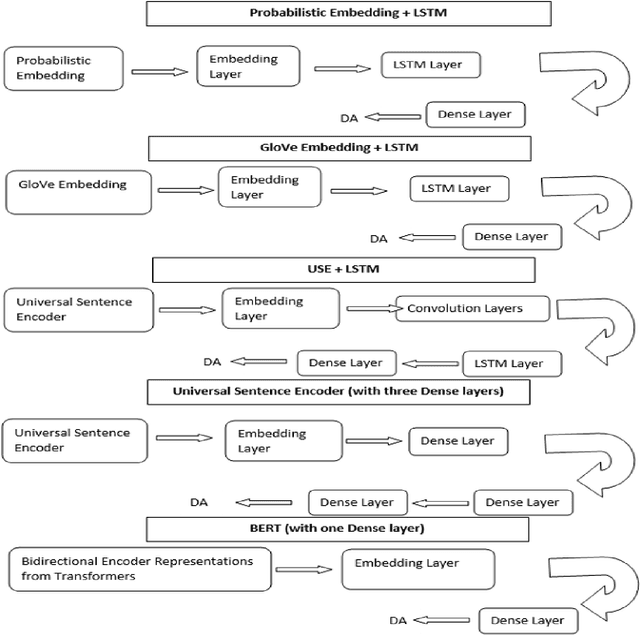
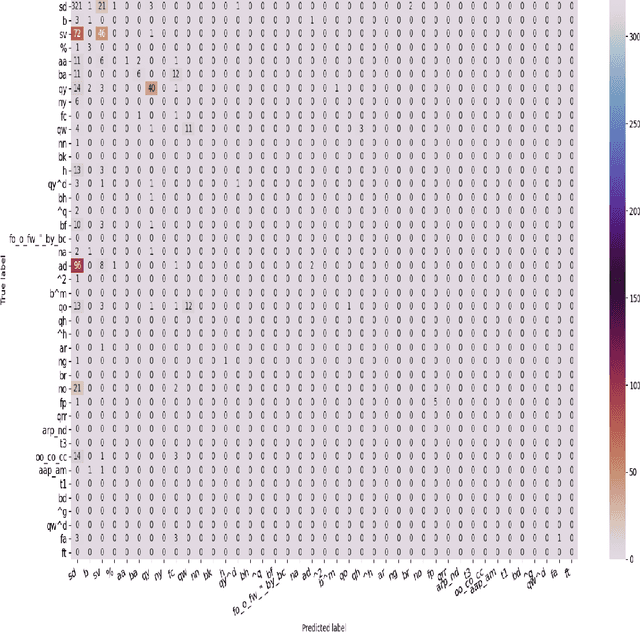

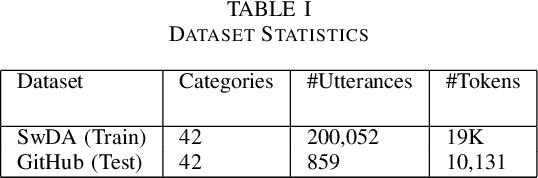
Social coding platforms, such as GitHub, serve as laboratories for studying collaborative problem solving in open source software development; a key feature is their ability to support issue reporting which is used by teams to discuss tasks and ideas. Analyzing the dialogue between team members, as expressed in issue comments, can yield important insights about the performance of virtual teams. This paper presents a transfer learning approach for performing dialogue act classification on issue comments. Since no large labeled corpus of GitHub issue comments exists, employing transfer learning enables us to leverage standard dialogue act datasets in combination with our own GitHub comment dataset. We compare the performance of several word and sentence level encoding models including Global Vectors for Word Representations (GloVe), Universal Sentence Encoder (USE), and Bidirectional Encoder Representations from Transformers (BERT). Being able to map the issue comments to dialogue acts is a useful stepping stone towards understanding cognitive team processes.