 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Image Generation by Spatial Transformation in Perceptual Colorspaces
Oct 21, 2023
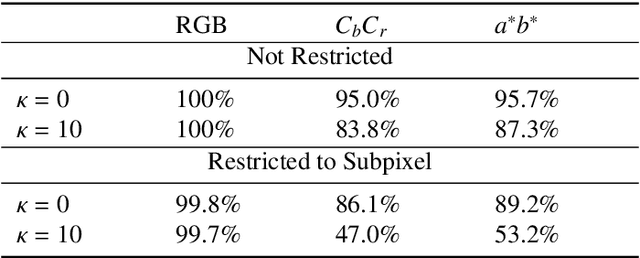

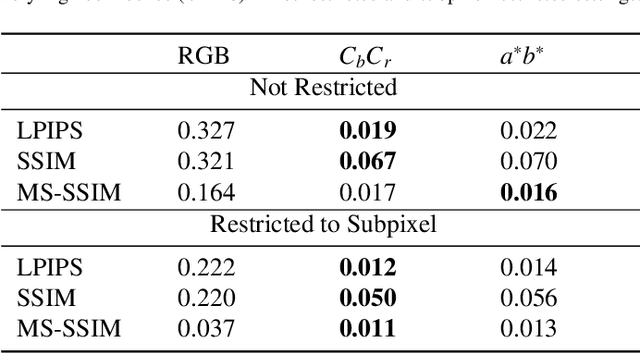
Deep neural networks are known to be vulnerable to adversarial perturbations. The amount of these perturbations are generally quantified using $L_p$ metrics, such as $L_0$, $L_2$ and $L_\infty$. However, even when the measured perturbations are small, they tend to be noticeable by human observers since $L_p$ distance metrics are not representative of human perception. On the other hand, humans are less sensitive to changes in colorspace. In addition, pixel shifts in a constrained neighborhood are hard to notice. Motivated by these observations, we propose a method that creates adversarial examples by applying spatial transformations, which creates adversarial examples by changing the pixel locations independently to chrominance channels of perceptual colorspaces such as $YC_{b}C_{r}$ and $CIELAB$, instead of making an additive perturbation or manipulating pixel values directly. In a targeted white-box attack setting, the proposed method is able to obtain competitive fooling rates with very high confidence. The experimental evaluations show that the proposed method has favorable results in terms of approximate perceptual distance between benign and adversarially generated images. The source code is publicly available at https://github.com/ayberkydn/stadv-torch
Imperceptible Adversarial Examples by Spatial Chroma-Shift
Sep 02, 2021
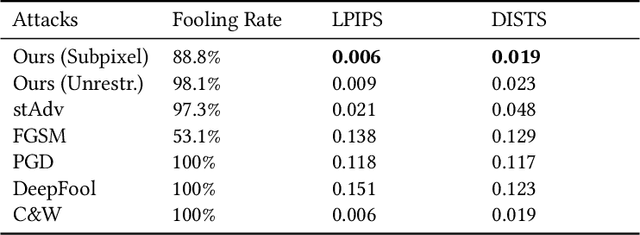

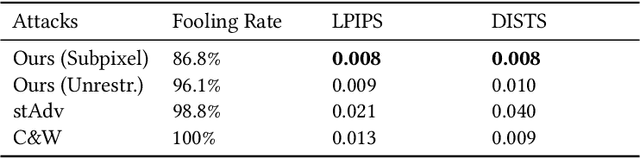
Deep Neural Networks have been shown to be vulnerable to various kinds of adversarial perturbations. In addition to widely studied additive noise based perturbations, adversarial examples can also be created by applying a per pixel spatial drift on input images. While spatial transformation based adversarial examples look more natural to human observers due to absence of additive noise, they still possess visible distortions caused by spatial transformations. Since the human vision is more sensitive to the distortions in the luminance compared to those in chrominance channels, which is one of the main ideas behind the lossy visual multimedia compression standards, we propose a spatial transformation based perturbation method to create adversarial examples by only modifying the color components of an input image. While having competitive fooling rates on CIFAR-10 and NIPS2017 Adversarial Learning Challenge datasets, examples created with the proposed method have better scores with regards to various perceptual quality metrics. Human visual perception studies validate that the examples are more natural looking and often indistinguishable from their original counterparts.