 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition
Feb 25, 2021
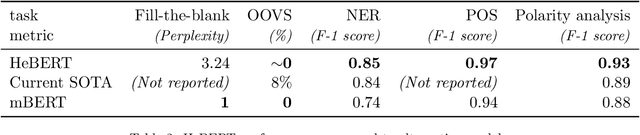
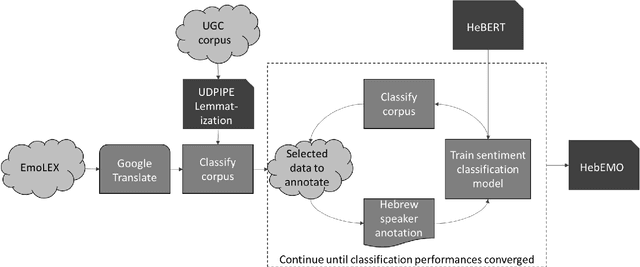
This paper introduces HeBERT and HebEMO. HeBERT is a Transformer-based model for modern Hebrew text, which relies on a BERT (Bidirectional Encoder Representations for Transformers) architecture. BERT has been shown to outperform alternative architectures in sentiment analysis, and is suggested to be particularly appropriate for MRLs. Analyzing multiple BERT specifications, we find that while model complexity correlates with high performance on language tasks that aim to understand terms in a sentence, a more-parsimonious model better captures the sentiment of entire sentence. Either way, out BERT-based language model outperforms all existing Hebrew alternatives on all common language tasks. HebEMO is a tool that uses HeBERT to detect polarity and extract emotions from Hebrew UGC. HebEMO is trained on a unique Covid-19-related UGC dataset that we collected and annotated for this study. Data collection and annotation followed an active learning procedure that aimed to maximize predictability. We show that HebEMO yields a high F1-score of 0.96 for polarity classification. Emotion detection reaches F1-scores of 0.78-0.97 for various target emotions, with the exception of surprise, which the model failed to capture (F1 = 0.41). These results are better than the best-reported performance, even among English-language models of emotion detection.