 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Bregman Clustering
Dec 11, 2018
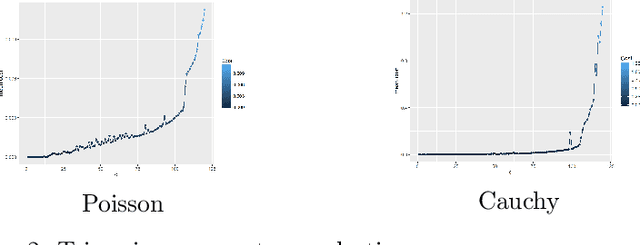
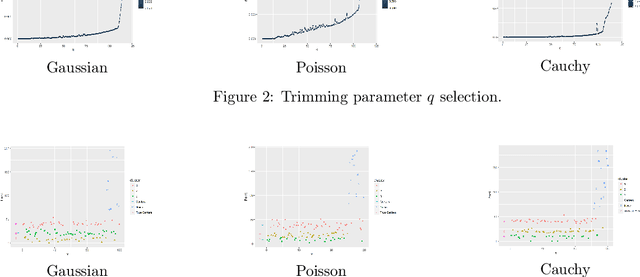

Using a trimming approach, we investigate a k-means type method based on Bregman divergences for clustering data possibly corrupted with clutter noise. The main interest of Bregman divergences is that the standard Lloyd algorithm adapts to these distortion measures, and they are well-suited for clustering data sampled according to mixture models from exponential families. We prove that there exists an optimal codebook, and that an empirically optimal codebook converges a.s. to an optimal codebook in the distortion sense. Moreover, we obtain the sub-Gaussian rate of convergence for k-means 1 $\sqrt$ n under mild tail assumptions. Also, we derive a Lloyd-type algorithm with a trimming parameter that can be selected from data according to some heuristic, and present some experimental results.
Aggregation using input-output trade-off
Mar 08, 2018



In this paper, we introduce a new learning strategy based on a seminal idea of Mojirsheibani (1999, 2000, 2002a, 2002b), who proposed a smart method for combining several classifiers, relying on a consensus notion. In many aggregation methods, the prediction for a new observation x is computed by building a linear or convex combination over a collection of basic estimators r1(x),. .. , rm(x) previously calibrated using a training data set. Mojirsheibani proposes to compute the prediction associated to a new observation by combining selected outputs of the training examples. The output of a training example is selected if some kind of consensus is observed: the predictions computed for the training example with the different machines have to be "similar" to the prediction for the new observation. This approach has been recently extended to the context of regression in Biau et al. (2016). In the original scheme, the agreement condition is actually required to hold for all individual estimators, which appears inadequate if there is one bad initial estimator. In practice, a few disagreements are allowed ; for establishing the theoretical results, the proportion of estimators satisfying the condition is required to tend to 1. In this paper, we propose an alternative procedure, mixing the previous consensus ideas on the predictions with the Euclidean distance computed between entries. This may be seen as an alternative approach allowing to reduce the effect of a possibly bad estimator in the initial list, using a constraint on the inputs. We prove the consistency of our strategy in classification and in regression. We also provide some numerical experiments on simulated and real data to illustrate the benefits of this new aggregation method. On the whole, our practical study shows that our method may perform much better than the original combination technique, and, in particular, exhibit far less variance. We also show on simulated examples that this procedure mixing inputs and outputs is still robust to high dimensional inputs.
Statistical learning for wind power : a modeling and stability study towards forecasting
Jan 12, 2018

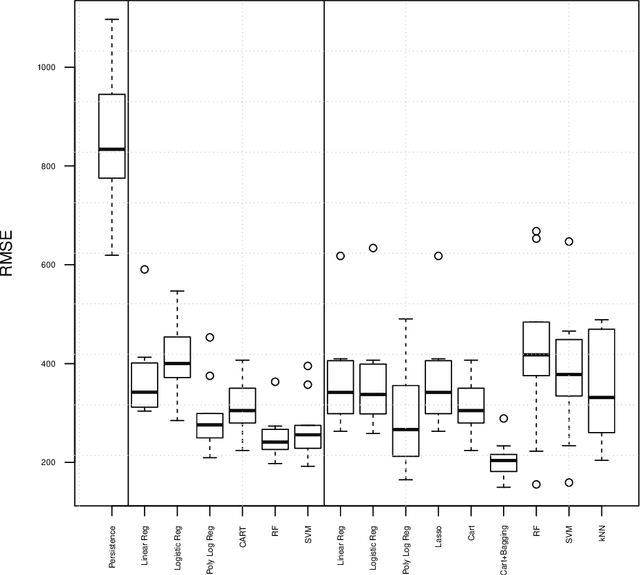

We focus on wind power modeling using machine learning techniques. We show on real data provided by the wind energy company Ma{\"i}a Eolis, that parametric models, even following closely the physical equation relating wind production to wind speed are outperformed by intelligent learning algorithms. In particular, the CART-Bagging algorithm gives very stable and promising results. Besides, as a step towards forecast, we quantify the impact of using deteriorated wind measures on the performances. We show also on this application that the default methodology to select a subset of predictors provided in the standard random forest package can be refined, especially when there exists among the predictors one variable which has a major impact.