 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing an Automatic Grading Model with deep Reinforcement Learning
May 11, 2024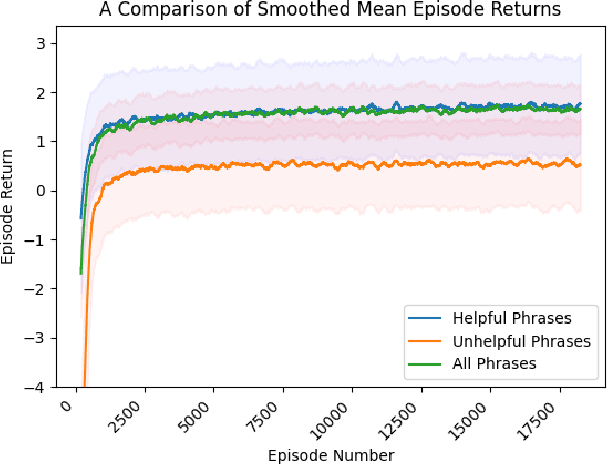
We explore the use of deep reinforcement learning to audit an automatic short answer grading (ASAG) model. Automatic grading may decrease the time burden of rating open-ended items for educators, but a lack of robust evaluation methods for these models can result in uncertainty of their quality. Current state-of-the-art ASAG models are configured to match human ratings from a training set, and researchers typically assess their quality with accuracy metrics that signify agreement between model and human scores. In this paper, we show that a high level of agreement to human ratings does not give sufficient evidence that an ASAG model is infallible. We train a reinforcement learning agent to revise student responses with the objective of achieving a high rating from an automatic grading model in the least number of revisions. By analyzing the agent's revised responses that achieve a high grade from the ASAG model but would not be considered a high scoring responses according to a scoring rubric, we discover ways in which the automated grader can be exploited, exposing shortcomings in the grading model.
Explainable Automatic Grading with Neural Additive Models
May 01, 2024
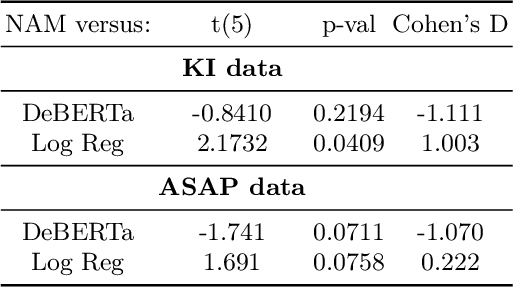
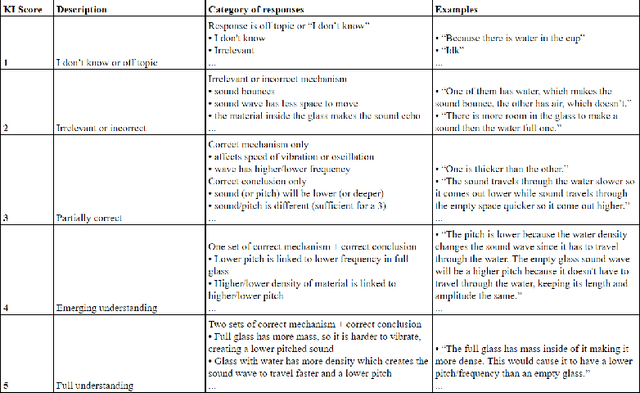
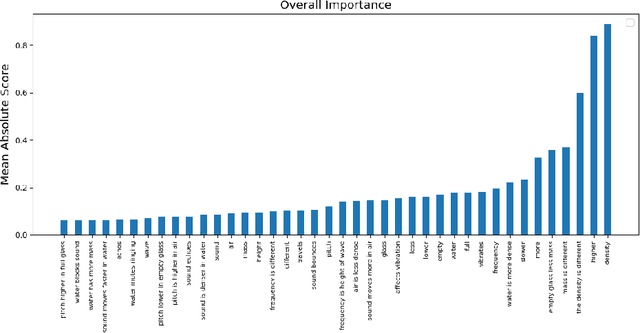
The use of automatic short answer grading (ASAG) models may help alleviate the time burden of grading while encouraging educators to frequently incorporate open-ended items in their curriculum. However, current state-of-the-art ASAG models are large neural networks (NN) often described as "black box", providing no explanation for which characteristics of an input are important for the produced output. This inexplicable nature can be frustrating to teachers and students when trying to interpret, or learn from an automatically-generated grade. To create a powerful yet intelligible ASAG model, we experiment with a type of model called a Neural Additive Model that combines the performance of a NN with the explainability of an additive model. We use a Knowledge Integration (KI) framework from the learning sciences to guide feature engineering to create inputs that reflect whether a student includes certain ideas in their response. We hypothesize that indicating the inclusion (or exclusion) of predefined ideas as features will be sufficient for the NAM to have good predictive power and interpretability, as this may guide a human scorer using a KI rubric. We compare the performance of the NAM with another explainable model, logistic regression, using the same features, and to a non-explainable neural model, DeBERTa, that does not require feature engineering.