 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing an Automatic Grading Model with deep Reinforcement Learning
Paper and Code
May 11, 2024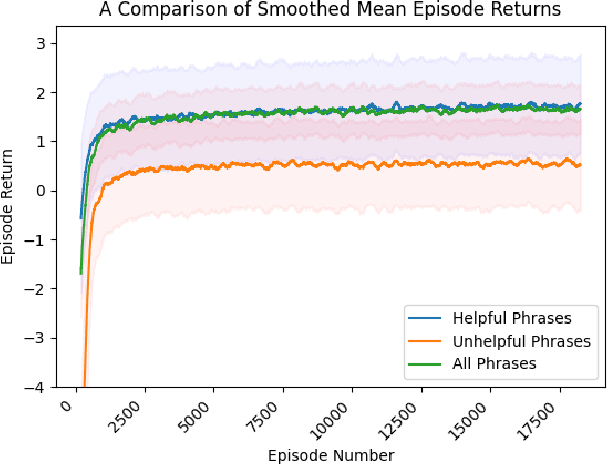
We explore the use of deep reinforcement learning to audit an automatic short answer grading (ASAG) model. Automatic grading may decrease the time burden of rating open-ended items for educators, but a lack of robust evaluation methods for these models can result in uncertainty of their quality. Current state-of-the-art ASAG models are configured to match human ratings from a training set, and researchers typically assess their quality with accuracy metrics that signify agreement between model and human scores. In this paper, we show that a high level of agreement to human ratings does not give sufficient evidence that an ASAG model is infallible. We train a reinforcement learning agent to revise student responses with the objective of achieving a high rating from an automatic grading model in the least number of revisions. By analyzing the agent's revised responses that achieve a high grade from the ASAG model but would not be considered a high scoring responses according to a scoring rubric, we discover ways in which the automated grader can be exploited, exposing shortcomings in the grading model.