 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric LLM Evaluation from Preference Data
Jan 29, 2026Evaluating the performance of large language models (LLMs) from human preference data is crucial for obtaining LLM leaderboards. However, many existing approaches either rely on restrictive parametric assumptions or lack valid uncertainty quantification when flexible machine learning methods are used. In this paper, we propose a nonparametric statistical framework, DMLEval, for comparing and ranking LLMs from preference data using debiased machine learning (DML). For this, we introduce generalized average ranking scores (GARS), which generalize commonly used ranking models, including the Bradley-Terry model or PageRank/ Rank centrality, with complex human responses such as ties. DMLEval comes with the following advantages: (i) It produces statistically efficient estimates of GARS ranking scores. (ii) It naturally allows the incorporation of black-box machine learning methods for estimation. (iii) It can be combined with pre-trained LLM evaluators (e.g., using LLM-as-a-judge). (iv) It suggests optimal policies for collecting preference data under budget constraints. We demonstrate these advantages both theoretically and empirically using both synthetic and real-world preference datasets. In summary, our framework provides practitioners with powerful, state-of-the-art methods for comparing or ranking LLMs.
Contextual Metric Meta-Evaluation by Measuring Local Metric Accuracy
Mar 25, 2025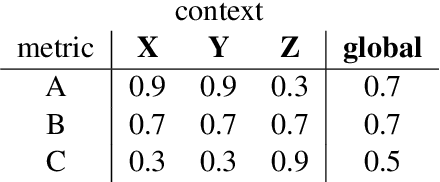
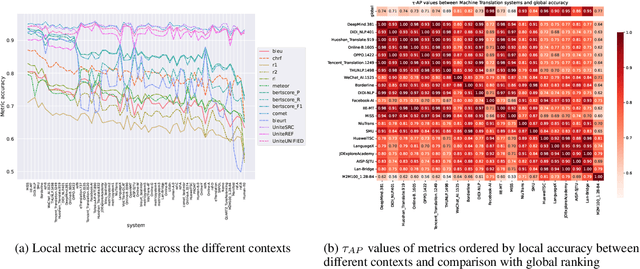

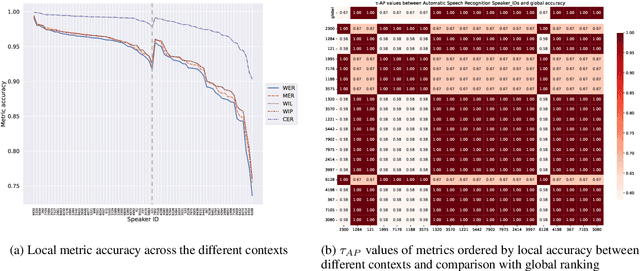
Meta-evaluation of automatic evaluation metrics -- assessing evaluation metrics themselves -- is crucial for accurately benchmarking natural language processing systems and has implications for scientific inquiry, production model development, and policy enforcement. While existing approaches to metric meta-evaluation focus on general statements about the absolute and relative quality of metrics across arbitrary system outputs, in practice, metrics are applied in highly contextual settings, often measuring the performance for a highly constrained set of system outputs. For example, we may only be interested in evaluating a specific model or class of models. We introduce a method for contextual metric meta-evaluation by comparing the local metric accuracy of evaluation metrics. Across translation, speech recognition, and ranking tasks, we demonstrate that the local metric accuracies vary both in absolute value and relative effectiveness as we shift across evaluation contexts. This observed variation highlights the importance of adopting context-specific metric evaluations over global ones.
How Real is Real: Evaluating the Robustness of Real-World Super Resolution
Oct 22, 2022Image super-resolution (SR) is a field in computer vision that focuses on reconstructing high-resolution images from the respective low-resolution image. However, super-resolution is a well-known ill-posed problem as most methods rely on the downsampling method performed on the high-resolution image to form the low-resolution image to be known. Unfortunately, this is not something that is available in real-life super-resolution applications such as increasing the quality of a photo taken on a mobile phone. In this paper we will evaluate multiple state-of-the-art super-resolution methods and gauge their performance when presented with various types of real-life images and discuss the benefits and drawbacks of each method. We also introduce a novel dataset, WideRealSR, containing real images from a wide variety of sources. Finally, through careful experimentation and evaluation, we will present a potential solution to alleviate the generalization problem which is imminent in most state-of-the-art super-resolution models.
Assessing Dataset Bias in Computer Vision
May 03, 2022

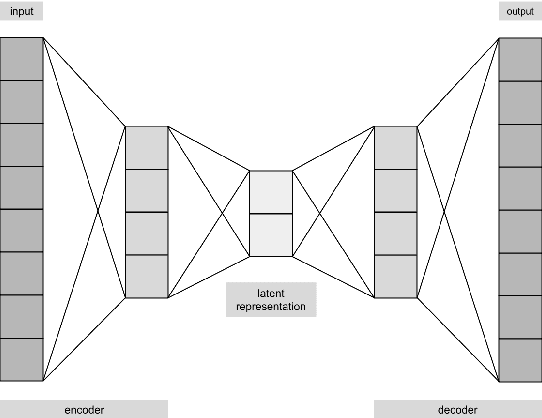
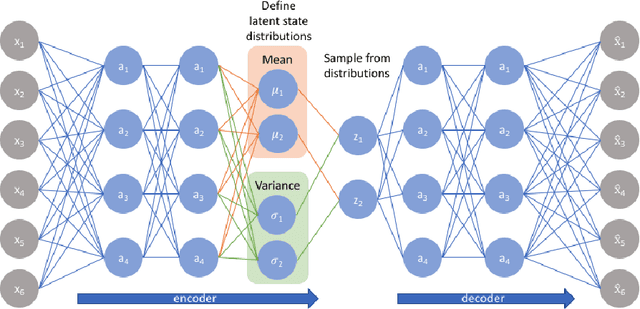
A biased dataset is a dataset that generally has attributes with an uneven class distribution. These biases have the tendency to propagate to the models that train on them, often leading to a poor performance in the minority class. In this project, we will explore the extent to which various data augmentation methods alleviate intrinsic biases within the dataset. We will apply several augmentation techniques on a sample of the UTKFace dataset, such as undersampling, geometric transformations, variational autoencoders (VAEs), and generative adversarial networks (GANs). We then trained a classifier for each of the augmented datasets and evaluated their performance on the native test set and on external facial recognition datasets. We have also compared their performance to the state-of-the-art attribute classifier trained on the FairFace dataset. Through experimentation, we were able to find that training the model on StarGAN-generated images led to the best overall performance. We also found that training on geometrically transformed images lead to a similar performance with a much quicker training time. Additionally, the best performing models also exhibit a uniform performance across the classes within each attribute. This signifies that the model was also able to mitigate the biases present in the baseline model that was trained on the original training set. Finally, we were able to show that our model has a better overall performance and consistency on age and ethnicity classification on multiple datasets when compared with the FairFace model. Our final model has an accuracy on the UTKFace test set of 91.75%, 91.30%, and 87.20% for the gender, age, and ethnicity attribute respectively, with a standard deviation of less than 0.1 between the accuracies of the classes of each attribute.