 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Plagiarism Detection in Marathi with a Weighted Ensemble of TF-IDF and BERT Embeddings for Low-Resource Language Processing
Jan 09, 2025Plagiarism involves using another person's work or concepts without proper attribution, presenting them as original creations. With the growing amount of data communicated in regional languages such as Marathi -- one of India's regional languages -- it is crucial to design robust plagiarism detection systems tailored for low-resource languages. Language models like Bidirectional Encoder Representations from Transformers (BERT) have demonstrated exceptional capability in text representation and feature extraction, making them essential tools for semantic analysis and plagiarism detection. However, the application of BERT for low-resource languages remains under-explored, particularly in the context of plagiarism detection. This paper presents a method to enhance the accuracy of plagiarism detection for Marathi texts using BERT sentence embeddings in conjunction with Term Frequency-Inverse Document Frequency (TF-IDF) feature representation. This approach effectively captures statistical, semantic, and syntactic aspects of text features through a weighted voting ensemble of machine learning models.
BERTopic for Topic Modeling of Hindi Short Texts: A Comparative Study
Jan 07, 2025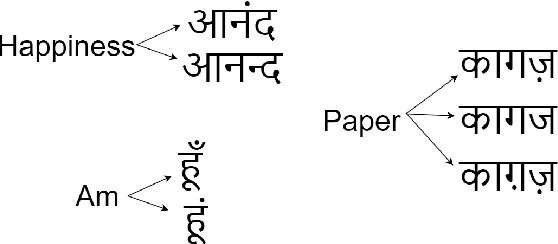
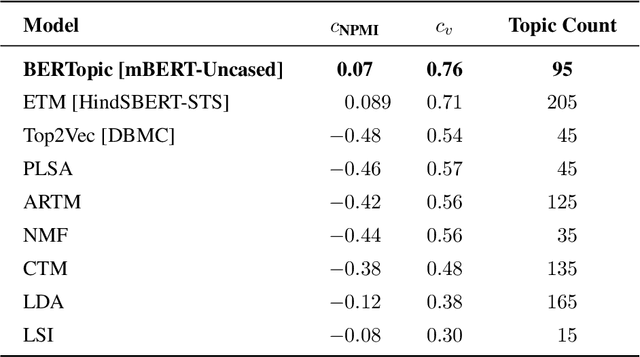
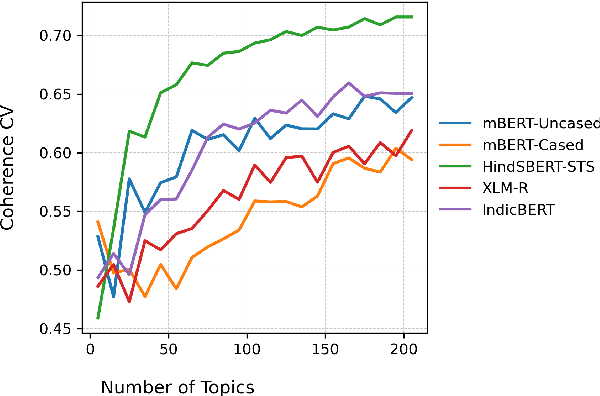
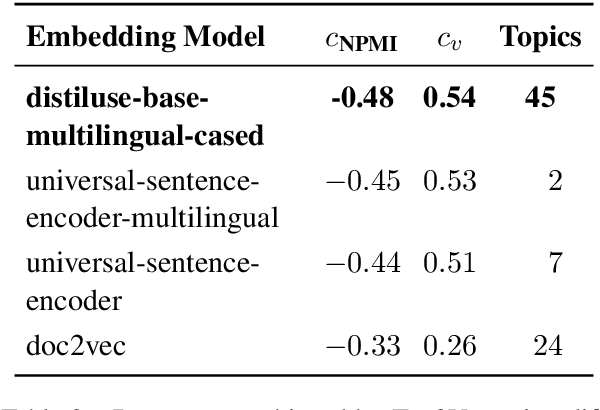
As short text data in native languages like Hindi increasingly appear in modern media, robust methods for topic modeling on such data have gained importance. This study investigates the performance of BERTopic in modeling Hindi short texts, an area that has been under-explored in existing research. Using contextual embeddings, BERTopic can capture semantic relationships in data, making it potentially more effective than traditional models, especially for short and diverse texts. We evaluate BERTopic using 6 different document embedding models and compare its performance against 8 established topic modeling techniques, such as Latent Dirichlet Allocation (LDA), Non-negative Matrix Factorization (NMF), Latent Semantic Indexing (LSI), Additive Regularization of Topic Models (ARTM), Probabilistic Latent Semantic Analysis (PLSA), Embedded Topic Model (ETM), Combined Topic Model (CTM), and Top2Vec. The models are assessed using coherence scores across a range of topic counts. Our results reveal that BERTopic consistently outperforms other models in capturing coherent topics from short Hindi texts.