 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View MRI Approach for Classification of MGMT Methylation in Glioblastoma Patients
Dec 16, 2025The presence of MGMT promoter methylation significantly affects how well chemotherapy works for patients with Glioblastoma Multiforme (GBM). Currently, confirmation of MGMT promoter methylation relies on invasive brain tumor tissue biopsies. In this study, we explore radiogenomics techniques, a promising approach in precision medicine, to identify genetic markers from medical images. Using MRI scans and deep learning models, we propose a new multi-view approach that considers spatial relationships between MRI views to detect MGMT methylation status. Importantly, our method extracts information from all three views without using a complicated 3D deep learning model, avoiding issues associated with high parameter count, slow convergence, and substantial memory demands. We also introduce a new technique for tumor slice extraction and show its superiority over existing methods based on multiple evaluation metrics. By comparing our approach to state-of-the-art models, we demonstrate the efficacy of our method. Furthermore, we share a reproducible pipeline of published models, encouraging transparency and the development of robust diagnostic tools. Our study highlights the potential of non-invasive methods for identifying MGMT promoter methylation and contributes to advancing precision medicine in GBM treatment.
MiniGPT-Med: Large Language Model as a General Interface for Radiology Diagnosis
Jul 04, 2024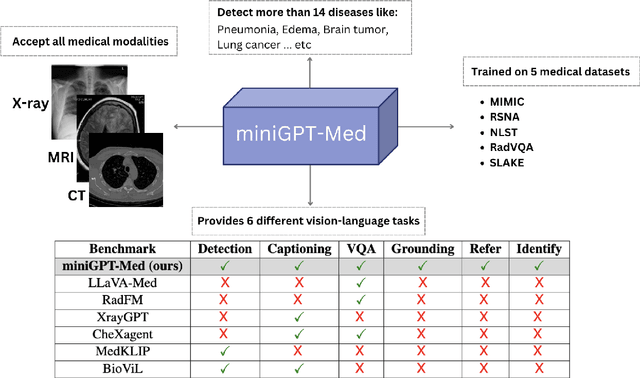

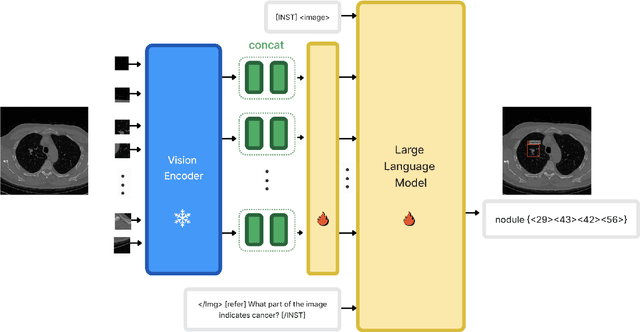
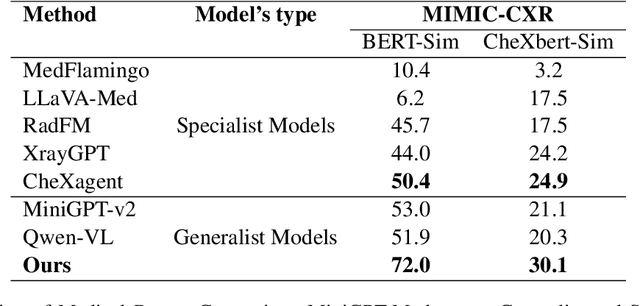
Recent advancements in artificial intelligence (AI) have precipitated significant breakthroughs in healthcare, particularly in refining diagnostic procedures. However, previous studies have often been constrained to limited functionalities. This study introduces MiniGPT-Med, a vision-language model derived from large-scale language models and tailored for medical applications. MiniGPT-Med demonstrates remarkable versatility across various imaging modalities, including X-rays, CT scans, and MRIs, enhancing its utility. The model is capable of performing tasks such as medical report generation, visual question answering (VQA), and disease identification within medical imagery. Its integrated processing of both image and textual clinical data markedly improves diagnostic accuracy. Our empirical assessments confirm MiniGPT-Med's superior performance in disease grounding, medical report generation, and VQA benchmarks, representing a significant step towards reducing the gap in assisting radiology practice. Furthermore, it achieves state-of-the-art performance on medical report generation, higher than the previous best model by 19\% accuracy. MiniGPT-Med promises to become a general interface for radiology diagnoses, enhancing diagnostic efficiency across a wide range of medical imaging applications.