 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaturalization of Text by the Insertion of Pauses and Filler Words
Nov 07, 2020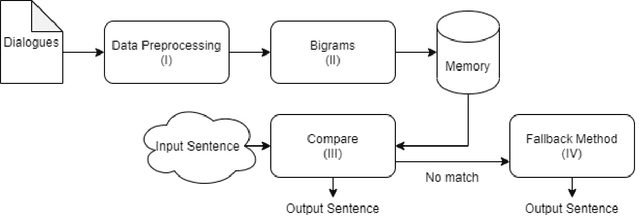
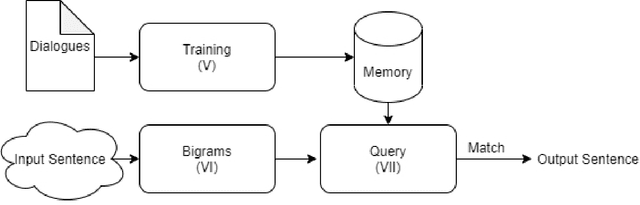
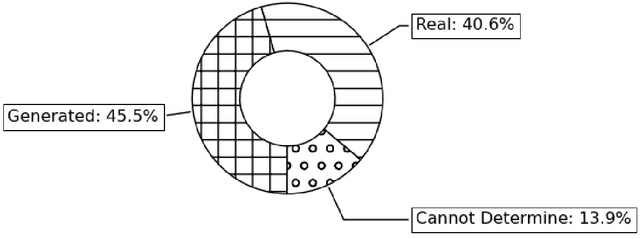
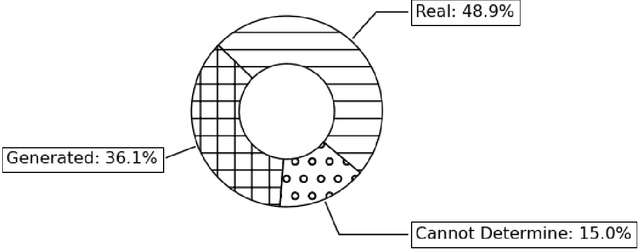
In this article, we introduce a set of methods to naturalize text based on natural human speech. Voice-based interactions provide a natural way of interfacing with electronic systems and are seeing a widespread adaptation of late. These computerized voices can be naturalized to some degree by inserting pauses and filler words at appropriate positions. The first proposed text transformation method uses the frequency of bigrams in the training data to make appropriate insertions in the input sentence. It uses a probability distribution to choose the insertions from a set of all possible insertions. This method is fast and can be included before a Text-To-Speech module. The second method uses a Recurrent Neural Network to predict the next word to be inserted. It confirms the insertions given by the bigram method. Additionally, the degree of naturalization can be controlled in both these methods. On the conduction of a blind survey, we conclude that the output of these text transformation methods is comparable to natural speech.