 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adapting Reinforcement Learning Agents to New Tasks: Insights from Q-Values
Jul 14, 2024

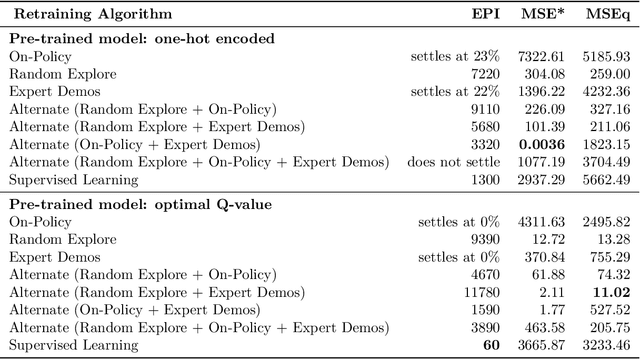

While contemporary reinforcement learning research and applications have embraced policy gradient methods as the panacea of solving learning problems, value-based methods can still be useful in many domains as long as we can wrangle with how to exploit them in a sample efficient way. In this paper, we explore the chaotic nature of DQNs in reinforcement learning, while understanding how the information that they retain when trained can be repurposed for adapting a model to different tasks. We start by designing a simple experiment in which we are able to observe the Q-values for each state and action in an environment. Then we train in eight different ways to explore how these training algorithms affect the way that accurate Q-values are learned (or not learned). We tested the adaptability of each trained model when retrained to accomplish a slightly modified task. We then scaled our setup to test the larger problem of an autonomous vehicle at an unprotected intersection. We observed that the model is able to adapt to new tasks quicker when the base model's Q-value estimates are closer to the true Q-values. The results provide some insights and guidelines into what algorithms are useful for sample efficient task adaptation.