 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Analysis on Contextual Self-Supervised Video Representation Learning
Apr 08, 2025Self-supervised learning has emerged as a powerful paradigm for label-free model pretraining, particularly in the video domain, where manual annotation is costly and time-intensive. However, existing self-supervised approaches employ diverse experimental setups, making direct comparisons challenging due to the absence of a standardized benchmark. In this work, we establish a unified benchmark that enables fair comparisons across different methods. Additionally, we systematically investigate five critical aspects of self-supervised learning in videos: (1) dataset size, (2) model complexity, (3) data distribution, (4) data noise, and (5) feature representations. To facilitate this study, we evaluate six self-supervised learning methods across six network architectures, conducting extensive experiments on five benchmark datasets and assessing performance on two distinct downstream tasks. Our analysis reveals key insights into the interplay between pretraining strategies, dataset characteristics, pretext tasks, and model architectures. Furthermore, we extend these findings to Video Foundation Models (ViFMs), demonstrating their relevance in large-scale video representation learning. Finally, leveraging these insights, we propose a novel approach that significantly reduces training data requirements while surpassing state-of-the-art methods that rely on 10% more pretraining data. We believe this work will guide future research toward a deeper understanding of self-supervised video representation learning and its broader implications.
Benchmarking self-supervised video representation learning
Jun 09, 2023



Self-supervised learning is an effective way for label-free model pre-training, especially in the video domain where labeling is expensive. Existing self-supervised works in the video domain use varying experimental setups to demonstrate their effectiveness and comparison across approaches becomes challenging with no standard benchmark. In this work, we first provide a benchmark that enables a comparison of existing approaches on the same ground. Next, we study five different aspects of self-supervised learning important for videos; 1) dataset size, 2) complexity, 3) data distribution, 4) data noise, and, 5)feature analysis. To facilitate this study, we focus on seven different methods along with seven different network architectures and perform an extensive set of experiments on 5 different datasets with an evaluation of two different downstream tasks. We present several interesting insights from this study which span across different properties of pretraining and target datasets, pretext-tasks, and model architectures among others. We further put some of these insights to the real test and propose an approach that requires a limited amount of training data and outperforms existing state-of-the-art approaches which use 10x pretraining data. We believe this work will pave the way for researchers to a better understanding of self-supervised pretext tasks in video representation learning.
A Computer Vision-Based Approach for Driver Distraction Recognition using Deep Learning and Genetic Algorithm Based Ensemble
Jul 28, 2021
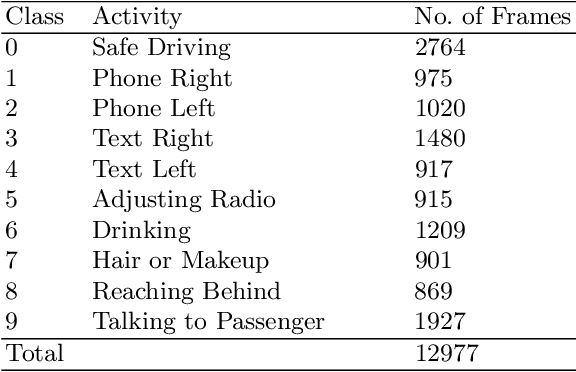
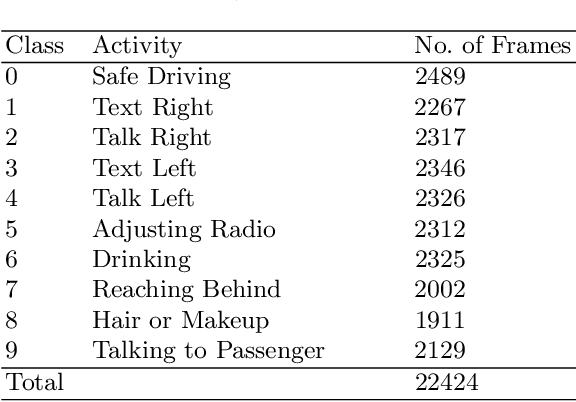
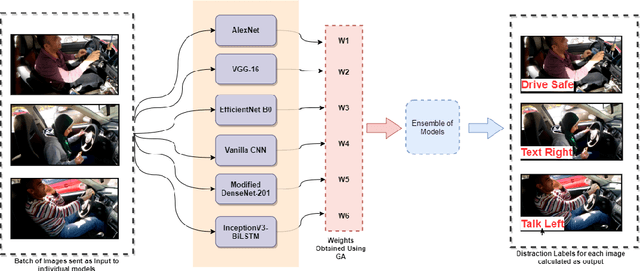
As the proportion of road accidents increases each year, driver distraction continues to be an important risk component in road traffic injuries and deaths. The distractions caused by the increasing use of mobile phones and other wireless devices pose a potential risk to road safety. Our current study aims to aid the already existing techniques in driver posture recognition by improving the performance in the driver distraction classification problem. We present an approach using a genetic algorithm-based ensemble of six independent deep neural architectures, namely, AlexNet, VGG-16, EfficientNet B0, Vanilla CNN, Modified DenseNet, and InceptionV3 + BiLSTM. We test it on two comprehensive datasets, the AUC Distracted Driver Dataset, on which our technique achieves an accuracy of 96.37%, surpassing the previously obtained 95.98%, and on the State Farm Driver Distraction Dataset, on which we attain an accuracy of 99.75%. The 6-Model Ensemble gave an inference time of 0.024 seconds as measured on our machine with Ubuntu 20.04(64-bit) and GPU as GeForce GTX 1080.