 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTragedy Plus Time: Capturing Unintended Human Activities from Weakly-labeled Videos
Apr 28, 2022

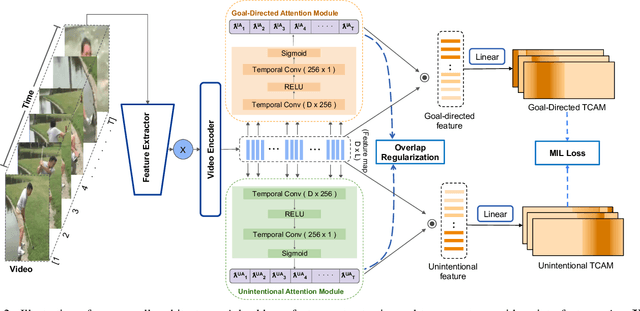
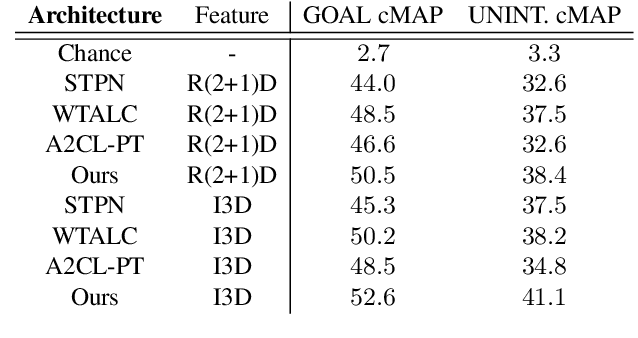
In videos that contain actions performed unintentionally, agents do not achieve their desired goals. In such videos, it is challenging for computer vision systems to understand high-level concepts such as goal-directed behavior, an ability present in humans from a very early age. Inculcating this ability in artificially intelligent agents would make them better social learners by allowing them to evaluate human action under a teleological lens. To validate the ability of deep learning models to perform this task, we curate the W-Oops dataset, built upon the Oops dataset [15]. W-Oops consists of 2,100 unintentional human action videos, with 44 goal-directed and 30 unintentional video-level activity labels collected through human annotations. Due to the expensive segment annotation procedure, we propose a weakly supervised algorithm for localizing the goal-directed as well as unintentional temporal regions in the video leveraging solely video-level labels. In particular, we employ an attention mechanism-based strategy that predicts the temporal regions which contribute the most to a classification task. Meanwhile, our designed overlap regularization allows the model to focus on distinct portions of the video for inferring the goal-directed and unintentional activity while guaranteeing their temporal ordering. Extensive quantitative experiments verify the validity of our localization method. We further conduct a video captioning experiment which demonstrates that the proposed localization module does indeed assist teleological action understanding.