 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal regularizations for data generation with probabilistic graphical models
Dec 02, 2021


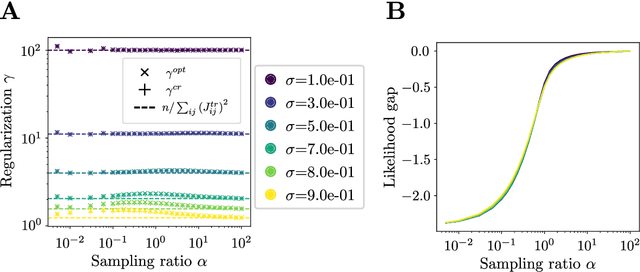
Understanding the role of regularization is a central question in Statistical Inference. Empirically, well-chosen regularization schemes often dramatically improve the quality of the inferred models by avoiding overfitting of the training data. We consider here the particular case of L 2 and L 1 regularizations in the Maximum A Posteriori (MAP) inference of generative pairwise graphical models. Based on analytical calculations on Gaussian multivariate distributions and numerical experiments on Gaussian and Potts models we study the likelihoods of the training, test, and 'generated data' (with the inferred models) sets as functions of the regularization strengths. We show in particular that, at its maximum, the test likelihood and the 'generated' likelihood, which quantifies the quality of the generated samples, have remarkably close values. The optimal value for the regularization strength is found to be approximately equal to the inverse sum of the squared couplings incoming on sites on the underlying network of interactions. Our results seem largely independent of the structure of the true underlying interactions that generated the data, of the regularization scheme considered, and are valid when small fluctuations of the posterior distribution around the MAP estimator are taken into account. Connections with empirical works on protein models learned from homologous sequences are discussed.
Low-Dimensional Manifolds Support Multiplexed Integrations in Recurrent Neural Networks
Nov 20, 2020



We study the learning dynamics and the representations emerging in Recurrent Neural Networks trained to integrate one or multiple temporal signals. Combining analytical and numerical investigations, we characterize the conditions under which a RNN with n neurons learns to integrate D(n) scalar signals of arbitrary duration. We show, both for linear and ReLU neurons, that its internal state lives close to a D-dimensional manifold, whose shape is related to the activation function. Each neuron therefore carries, to various degrees, information about the value of all integrals. We discuss the deep analogy between our results and the concept of mixed selectivity forged by computational neuroscientists to interpret cortical recordings.