 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate versus Politics: Detection of Hate against Policy makers in Italian tweets
Jul 12, 2021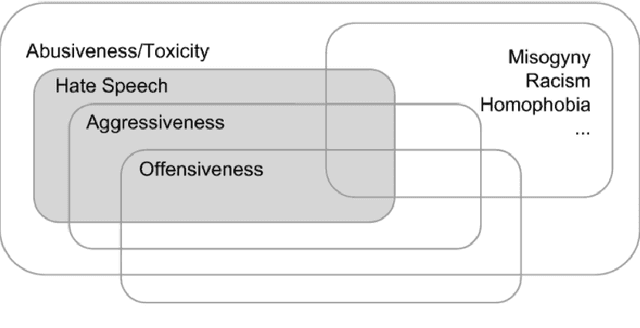



Accurate detection of hate speech against politicians, policy making and political ideas is crucial to maintain democracy and free speech. Unfortunately, the amount of labelled data necessary for training models to detect hate speech are limited and domain-dependent. In this paper, we address the issue of classification of hate speech against policy makers from Twitter in Italian, producing the first resource of this type in this language. We collected and annotated 1264 tweets, examined the cases of disagreements between annotators, and performed in-domain and cross-domain hate speech classifications with different features and algorithms. We achieved a performance of ROC AUC 0.83 and analyzed the most predictive attributes, also finding the different language features in the anti-policymakers and anti-immigration domains. Finally, we visualized networks of hashtags to capture the topics used in hateful and normal tweets.