 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Privacy-Preserving Collaborative Tree-based Model Learning
Mar 16, 2021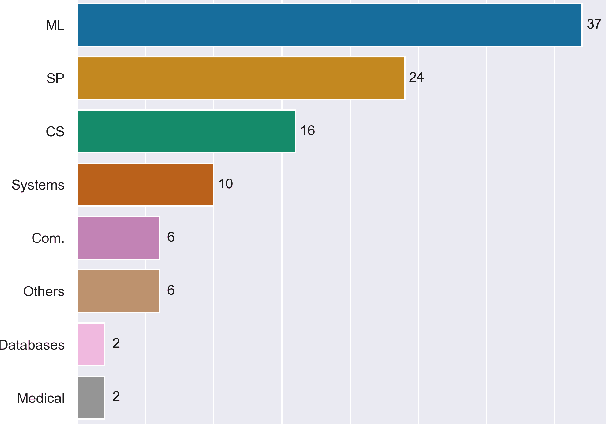

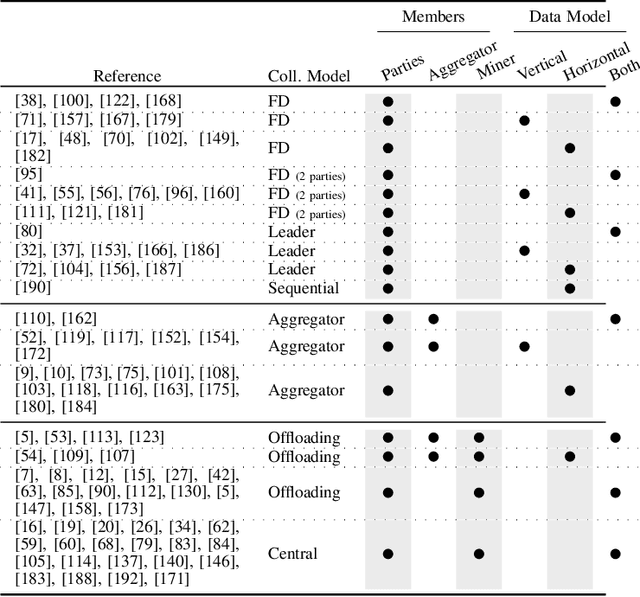
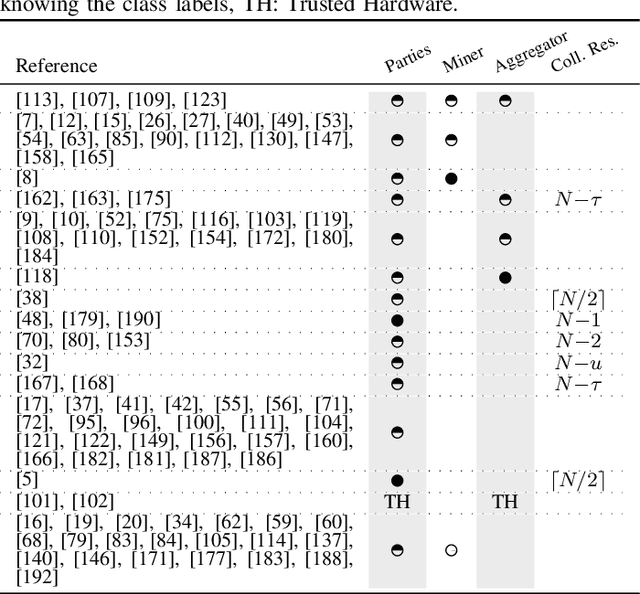
Tree-based models are among the most efficient machine learning techniques for data mining nowadays due to their accuracy, interpretability, and simplicity. The recent orthogonal needs for more data and privacy protection call for collaborative privacy-preserving solutions. In this work, we survey the literature on distributed and privacy-preserving training of tree-based models and we systematize its knowledge based on four axes: the learning algorithm, the collaborative model, the protection mechanism, and the threat model. We use this to identify the strengths and limitations of these works and provide for the first time a framework analyzing the information leakage occurring in distributed tree-based model learning.
POSEIDON: Privacy-Preserving Federated Neural Network Learning
Sep 30, 2020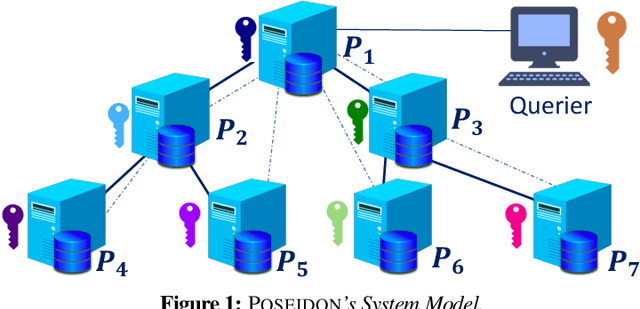



In this paper, we address the problem of privacy-preserving training and evaluation of neural networks in an $N$-party, federated learning setting. We propose a novel system, POSEIDON, the first of its kind in the regime of privacy-preserving neural network training, employing multiparty lattice-based cryptography and preserving the confidentiality of the training data, the model, and the evaluation data, under a passive-adversary model and collusions between up to $N-1$ parties. To efficiently execute the secure backpropagation algorithm for training neural networks, we provide a generic packing approach that enables Single Instruction, Multiple Data (SIMD) operations on encrypted data. We also introduce arbitrary linear transformations within the cryptographic bootstrapping operation, optimizing the costly cryptographic computations over the parties, and we define a constrained optimization problem for choosing the cryptographic parameters. Our experimental results show that POSEIDON achieves accuracy similar to centralized or decentralized non-private approaches and that its computation and communication overhead scales linearly with the number of parties. POSEIDON trains a 3-layer neural network on the MNIST dataset with 784 features and 60K samples distributed among 10 parties in less than 2 hours.
Building and Measuring Privacy-Preserving Predictive Blacklists
Oct 08, 2018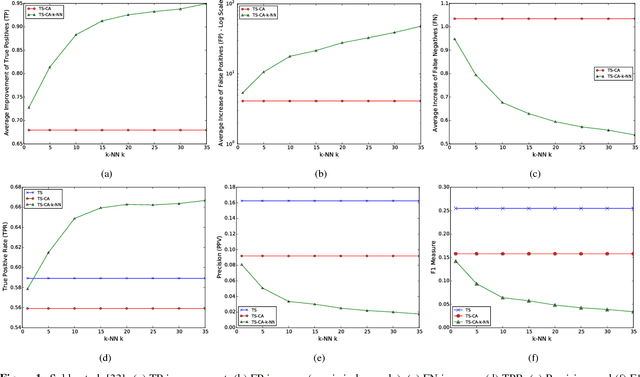
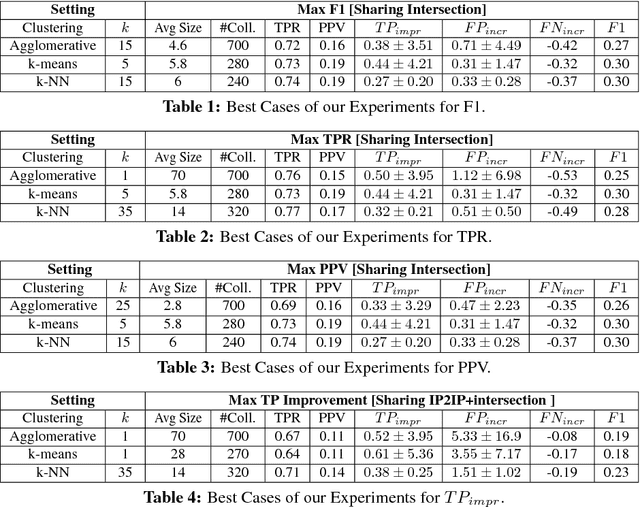
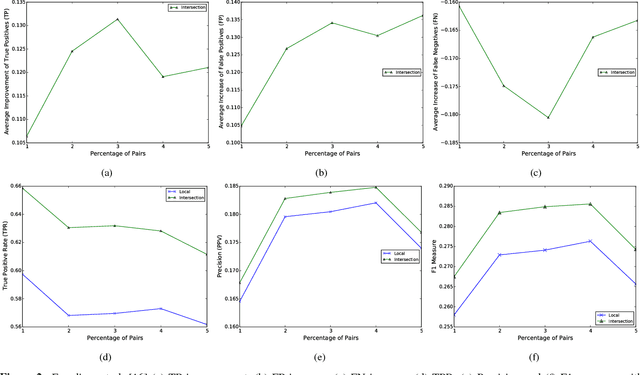
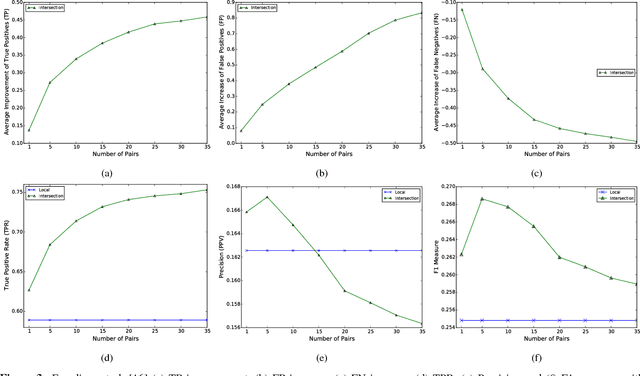
(Withdrawn) Collaborative security initiatives are increasingly often advocated to improve timeliness and effectiveness of threat mitigation. Among these, collaborative predictive blacklisting (CPB) aims to forecast attack sources based on alerts contributed by multiple organizations that might be targeted in similar ways. Alas, CPB proposals thus far have only focused on improving hit counts, but overlooked the impact of collaboration on false positives and false negatives. Moreover, sharing threat intelligence often prompts important privacy, confidentiality, and liability issues. In this paper, we first provide a comprehensive measurement analysis of two state-of-the-art CPB systems: one that uses a trusted central party to collect alerts [Soldo et al., Infocom'10] and a peer-to-peer one relying on controlled data sharing [Freudiger et al., DIMVA'15], studying the impact of collaboration on both correct and incorrect predictions. Then, we present a novel privacy-friendly approach that significantly improves over previous work, achieving a better balance of true and false positive rates, while minimizing information disclosure. Finally, we present an extension that allows our system to scale to very large numbers of organizations.
Privacy-Friendly Mobility Analytics using Aggregate Location Data
Oct 09, 2016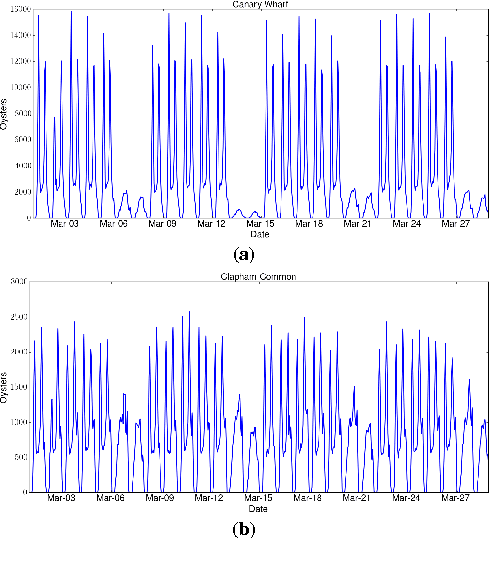

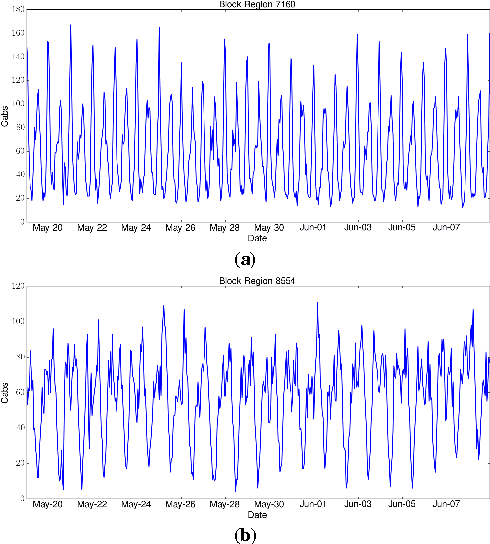

Location data can be extremely useful to study commuting patterns and disruptions, as well as to predict real-time traffic volumes. At the same time, however, the fine-grained collection of user locations raises serious privacy concerns, as this can reveal sensitive information about the users, such as, life style, political and religious inclinations, or even identities. In this paper, we study the feasibility of crowd-sourced mobility analytics over aggregate location information: users periodically report their location, using a privacy-preserving aggregation protocol, so that the server can only recover aggregates -- i.e., how many, but not which, users are in a region at a given time. We experiment with real-world mobility datasets obtained from the Transport For London authority and the San Francisco Cabs network, and present a novel methodology based on time series modeling that is geared to forecast traffic volumes in regions of interest and to detect mobility anomalies in them. In the presence of anomalies, we also make enhanced traffic volume predictions by feeding our model with additional information from correlated regions. Finally, we present and evaluate a mobile app prototype, called Mobility Data Donors (MDD), in terms of computation, communication, and energy overhead, demonstrating the real-world deployability of our techniques.