 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination is a Consequence of Space-Optimality: A Rate-Distortion Theorem for Membership Testing
Feb 03, 2026Large language models often hallucinate with high confidence on "random facts" that lack inferable patterns. We formalize the memorization of such facts as a membership testing problem, unifying the discrete error metrics of Bloom filters with the continuous log-loss of LLMs. By analyzing this problem in the regime where facts are sparse in the universe of plausible claims, we establish a rate-distortion theorem: the optimal memory efficiency is characterized by the minimum KL divergence between score distributions on facts and non-facts. This theoretical framework provides a distinctive explanation for hallucination: even with optimal training, perfect data, and a simplified "closed world" setting, the information-theoretically optimal strategy under limited capacity is not to abstain or forget, but to assign high confidence to some non-facts, resulting in hallucination. We validate this theory empirically on synthetic data, showing that hallucinations persist as a natural consequence of lossy compression.
Agnostic Learning of Arbitrary ReLU Activation under Gaussian Marginals
Nov 22, 2024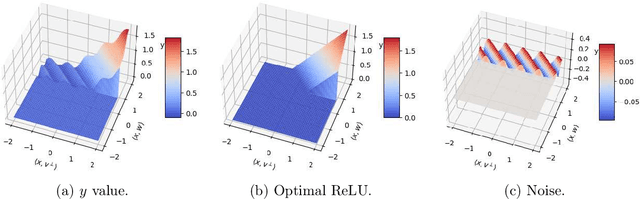
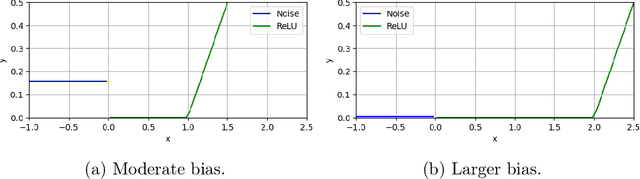
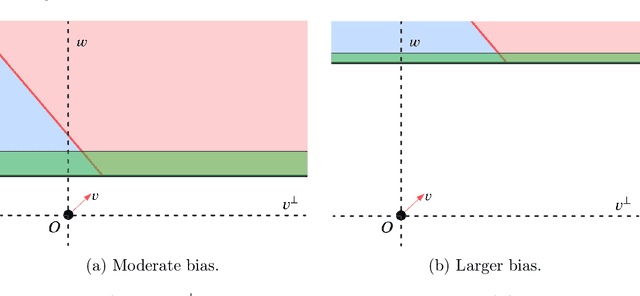
We consider the problem of learning an arbitrarily-biased ReLU activation (or neuron) over Gaussian marginals with the squared loss objective. Despite the ReLU neuron being the basic building block of modern neural networks, we still do not understand the basic algorithmic question of whether one arbitrary ReLU neuron is learnable in the non-realizable setting. In particular, all existing polynomial time algorithms only provide approximation guarantees for the better-behaved unbiased setting or restricted bias setting. Our main result is a polynomial time statistical query (SQ) algorithm that gives the first constant factor approximation for arbitrary bias. It outputs a ReLU activation that achieves a loss of $O(\mathrm{OPT}) + \varepsilon$ in time $\mathrm{poly}(d,1/\varepsilon)$, where $\mathrm{OPT}$ is the loss obtained by the optimal ReLU activation. Our algorithm presents an interesting departure from existing algorithms, which are all based on gradient descent and thus fall within the class of correlational statistical query (CSQ) algorithms. We complement our algorithmic result by showing that no polynomial time CSQ algorithm can achieve a constant factor approximation. Together, these results shed light on the intrinsic limitation of gradient descent, while identifying arguably the simplest setting (a single neuron) where there is a separation between SQ and CSQ algorithms.