 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Fine-Tuning Fails and when it Generalises: Role of Data Diversity and Mixed Training in LLM-based TTS
Mar 11, 2026Large language models are increasingly adopted as semantic backbones for neural text-to-speech systems. However, frozen LLM representations are insufficient for modeling speaker specific acoustic and perceptual characteristics. Our experiments involving fine tuning of the Language Model backbone of TTS show promise in improving the voice consistency and Signal to Noise ratio SNR in voice cloning task. Across multiple speakers LoRA finetuning consistently outperforms the non-finetuned base Qwen-0.5B model across three complementary dimensions of speech quality. First, perceptual quality improves significantly with DNS-MOS gains of up to 0.42 points for speakers whose training data exhibits sufficient acoustic variability. Second, speaker fidelity improves for all evaluated speakers with consistent increases in voice similarity indicating that LoRA effectively adapts speaker identity representations without degrading linguistic modeling. Third, signal level quality improves in most cases with signal to noise ratio increasing by as much as 34 percent. Crucially these improvements are strongly governed by the characteristics of the training data. Speakers with high variability in acoustic energy and perceptual quality achieve simultaneous gains in DNS-MOS voice similarity and SNR. Overall this work establishes that LoRA finetuning is not merely a parameter efficient optimization technique but an effective mechanism for better speaker level adaptation in compact LLM-based TTS systems. When supported by sufficiently diverse training data LoRA adapted Qwen-0.5B consistently surpasses its frozen base model in perceptual quality speaker similarity with low latency using GGUF model hosted in quantized form.
MM-tau-p$^2$: Persona-Adaptive Prompting for Robust Multi-Modal Agent Evaluation in Dual-Control Settings
Mar 11, 2026Current evaluation frameworks and benchmarks for LLM powered agents focus on text chat driven agents, these frameworks do not expose the persona of user to the agent, thus operating in a user agnostic environment. Importantly, in customer experience management domain, the agent's behaviour evolves as the agent learns about user personality. With proliferation of real time TTS and multi-modal language models, LLM based agents are gradually going to become multi-modal. Towards this, we propose the MM-tau-p$^2$ benchmark with metrics for evaluating the robustness of multi-modal agents in dual control setting with and without persona adaption of user, while also taking user inputs in the planning process to resolve a user query. In particular, our work shows that even with state of-the-art frontier LLMs like GPT-5, GPT 4.1, there are additional considerations measured using metrics viz. multi-modal robustness, turn overhead while introducing multi-modality into LLM based agents. Overall, MM-tau-p$^2$ builds on our prior work FOCAL and provides a holistic way of evaluating multi-modal agents in an automated way by introducing 12 novel metrics. We also provide estimates of these metrics on the telecom and retail domains by using the LLM-as-judge approach using carefully crafted prompts with well defined rubrics for evaluating each conversation.
M-PACE: Mother Child Framework for Multimodal Compliance
Sep 17, 2025Ensuring that multi-modal content adheres to brand, legal, or platform-specific compliance standards is an increasingly complex challenge across domains. Traditional compliance frameworks typically rely on disjointed, multi-stage pipelines that integrate separate modules for image classification, text extraction, audio transcription, hand-crafted checks, and rule-based merges. This architectural fragmentation increases operational overhead, hampers scalability, and hinders the ability to adapt to dynamic guidelines efficiently. With the emergence of Multimodal Large Language Models (MLLMs), there is growing potential to unify these workflows under a single, general-purpose framework capable of jointly processing visual and textual content. In light of this, we propose Multimodal Parameter Agnostic Compliance Engine (M-PACE), a framework designed for assessing attributes across vision-language inputs in a single pass. As a representative use case, we apply M-PACE to advertisement compliance, demonstrating its ability to evaluate over 15 compliance-related attributes. To support structured evaluation, we introduce a human-annotated benchmark enriched with augmented samples that simulate challenging real-world conditions, including visual obstructions and profanity injection. M-PACE employs a mother-child MLLM setup, demonstrating that a stronger parent MLLM evaluating the outputs of smaller child models can significantly reduce dependence on human reviewers, thereby automating quality control. Our analysis reveals that inference costs reduce by over 31 times, with the most efficient models (Gemini 2.0 Flash as child MLLM selected by mother MLLM) operating at 0.0005 per image, compared to 0.0159 for Gemini 2.5 Pro with comparable accuracy, highlighting the trade-off between cost and output quality achieved in real time by M-PACE in real life deployment over advertising data.
G-CSEA: A Graph-Based Conflict Set Extraction Algorithm for Identifying Infeasibility in Pseudo-Boolean Models
Sep 16, 2025Workforce scheduling involves a variety of rule-based constraints-such as shift limits, staffing policies, working hour restrictions, and many similar scheduling rules-which can interact in conflicting ways, leading to infeasible models. Identifying the underlying causes of such infeasibility is critical for resolving scheduling issues and restoring feasibility. A common diagnostic approach is to compute Irreducible Infeasible Subsets (IISs): minimal sets of constraints that are jointly infeasible but become feasible when any one is removed. We consider models formulated using pseudo-Boolean constraints with inequality relations over binary variables, which naturally encode scheduling logic. Existing IIS extraction methods such as Additive Deletion and QuickXplain rely on repeated feasibility checks, often incurring large numbers of solver calls. Dual ray analysis, while effective for LP-based models, may fail when the relaxed problem is feasible but the underlying pseudo-Boolean model is not. To address these limitations, we propose Graph-based Conflict Set Extraction Algorithm (G-CSEA) to extract a conflict set, an approach inspired by Conflict-Driven Clause Learning (CDCL) in SAT solvers. Our method constructs an implication graph during constraint propagation and, upon detecting a conflict, traces all contributing constraints across both decision branches. The resulting conflict set can optionally be minimized using QuickXplain to produce an IIS.
E-ARMOR: Edge case Assessment and Review of Multilingual Optical Character Recognition
Sep 03, 2025Optical Character Recognition (OCR) in multilingual, noisy, and diverse real-world images remains a significant challenge for optical character recognition systems. With the rise of Large Vision-Language Models (LVLMs), there is growing interest in their ability to generalize and reason beyond fixed OCR pipelines. In this work, we introduce Sprinklr-Edge-OCR, a novel OCR system built specifically optimized for edge deployment in resource-constrained environments. We present a large-scale comparative evaluation of five state-of-the-art LVLMs (InternVL, Qwen, GOT OCR, LLaMA, MiniCPM) and two traditional OCR systems (Sprinklr-Edge-OCR, SuryaOCR) on a proprietary, doubly hand annotated dataset of multilingual (54 languages) images. Our benchmark covers a broad range of metrics including accuracy, semantic consistency, language coverage, computational efficiency (latency, memory, GPU usage), and deployment cost. To better reflect real-world applicability, we also conducted edge case deployment analysis, evaluating model performance on CPU only environments. Among the results, Qwen achieved the highest precision (0.54), while Sprinklr-Edge-OCR delivered the best overall F1 score (0.46) and outperformed others in efficiency, processing images 35 faster (0.17 seconds per image on average) and at less than 0.01 of the cost (0.006 USD per 1,000 images) compared to LVLM. Our findings demonstrate that the most optimal OCR systems for edge deployment are the traditional ones even in the era of LLMs due to their low compute requirements, low latency, and very high affordability.
KnowsLM: A framework for evaluation of small language models for knowledge augmentation and humanised conversations
Apr 06, 2025In the evolving landscape of conversational AI, generating concise, context-aware, and human-like dialogue using small and medium-sized language models (LLMs) remains a complex challenge. This study investigates the influence of LoRA rank, dataset scale, and prompt prefix design on both knowledge retention and stylistic alignment. While fine-tuning improves fluency and enables stylistic customization, its ability to integrate unseen knowledge is constrained -- particularly with smaller datasets. Conversely, RAG-augmented models, equipped to incorporate external documents at inference, demonstrated superior factual accuracy on out-of-distribution prompts, though they lacked the stylistic consistency achieved by fine-tuning. Evaluations by LLM-based judges across knowledge accuracy, conversational quality, and conciseness suggest that fine-tuning is best suited for tone adaptation, whereas RAG excels at real-time knowledge augmentation.
CultureVo: The Serious Game of Utilizing Gen AI for Enhancing Cultural Intelligence
Aug 01, 2024

CultureVo, Inc. has developed the Integrated Culture Learning Suite (ICLS) to deliver foundational knowledge of world cultures through a combination of interactive lessons and gamified experiences. This paper explores how Generative AI powered by open source Large Langauge Models are utilized within the ICLS to enhance cultural intelligence. The suite employs Generative AI techniques to automate the assessment of learner knowledge, analyze behavioral patterns, and manage interactions with non-player characters using real time learner assessment. Additionally, ICLS provides contextual hint and recommend course content by assessing learner proficiency, while Generative AI facilitates the automated creation and validation of educational content.
Introducing a new hyper-parameter for RAG: Context Window Utilization
Jul 29, 2024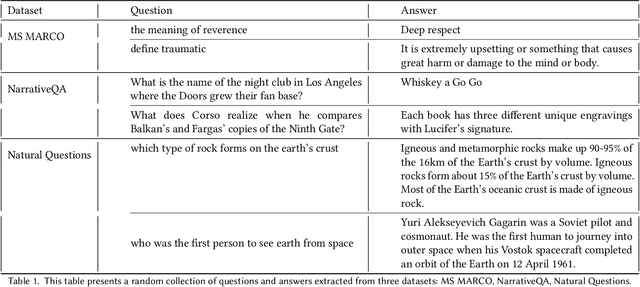
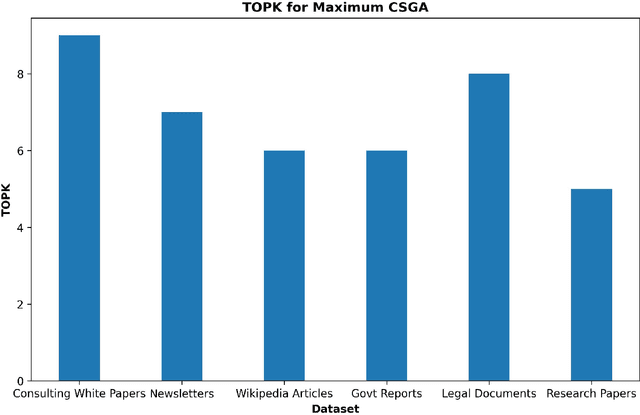

This paper introduces a new hyper-parameter for Retrieval-Augmented Generation (RAG) systems called Context Window Utilization. RAG systems enhance generative models by incorporating relevant information retrieved from external knowledge bases, improving the factual accuracy and contextual relevance of generated responses. The size of the text chunks retrieved and processed is a critical factor influencing RAG performance. This study aims to identify the optimal chunk size that maximizes answer generation quality. Through systematic experimentation, we analyze the effects of varying chunk sizes on the efficiency and effectiveness of RAG frameworks. Our findings reveal that an optimal chunk size balances the trade-off between providing sufficient context and minimizing irrelevant information. These insights are crucial for enhancing the design and implementation of RAG systems, underscoring the importance of selecting an appropriate chunk size to achieve superior performance.
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Jun 24, 2024Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
Evaluating the Efficacy of Open-Source LLMs in Enterprise-Specific RAG Systems: A Comparative Study of Performance and Scalability
Jun 17, 2024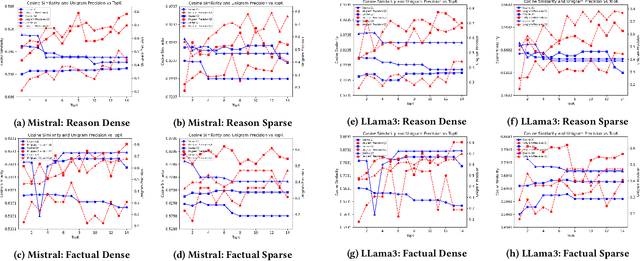
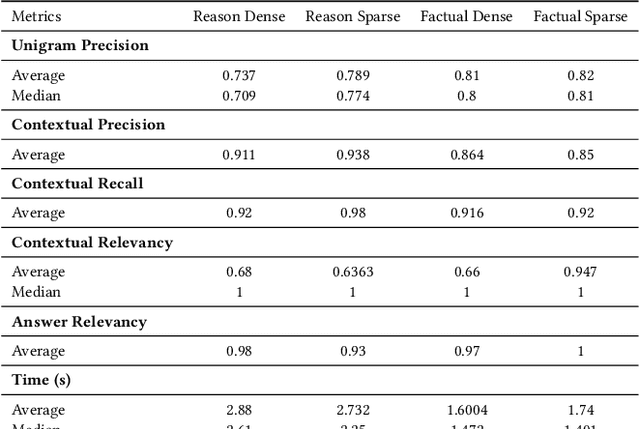
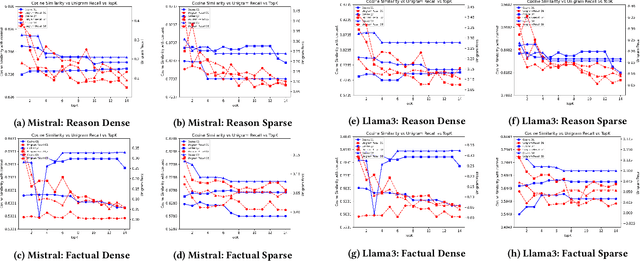
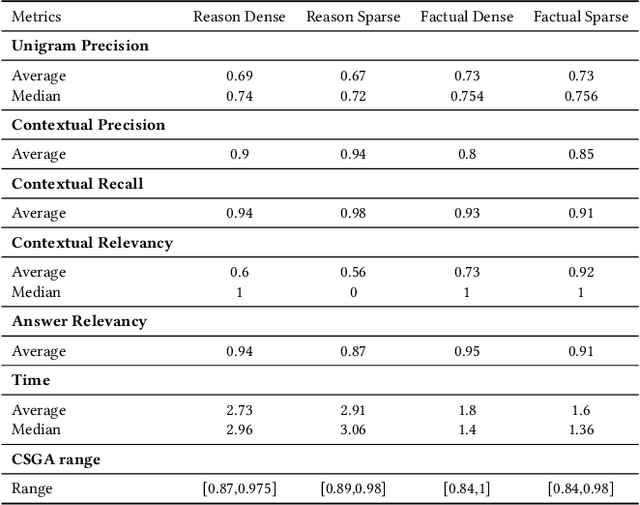
This paper presents an analysis of open-source large language models (LLMs) and their application in Retrieval-Augmented Generation (RAG) tasks, specific for enterprise-specific data sets scraped from their websites. With the increasing reliance on LLMs in natural language processing, it is crucial to evaluate their performance, accessibility, and integration within specific organizational contexts. This study examines various open-source LLMs, explores their integration into RAG frameworks using enterprise-specific data, and assesses the performance of different open-source embeddings in enhancing the retrieval and generation process. Our findings indicate that open-source LLMs, combined with effective embedding techniques, can significantly improve the accuracy and efficiency of RAG systems, offering a viable alternative to proprietary solutions for enterprises.