 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of the generalization error for deep gradient flow methods for PDEs
Dec 31, 2025The aim of this article is to provide a firm mathematical foundation for the application of deep gradient flow methods (DGFMs) for the solution of (high-dimensional) partial differential equations (PDEs). We decompose the generalization error of DGFMs into an approximation and a training error. We first show that the solution of PDEs that satisfy reasonable and verifiable assumptions can be approximated by neural networks, thus the approximation error tends to zero as the number of neurons tends to infinity. Then, we derive the gradient flow that the training process follows in the ``wide network limit'' and analyze the limit of this flow as the training time tends to infinity. These results combined show that the generalization error of DGFMs tends to zero as the number of neurons and the training time tend to infinity.
Improved model-free bounds for multi-asset options using option-implied information and deep learning
Apr 02, 2024



We consider the computation of model-free bounds for multi-asset options in a setting that combines dependence uncertainty with additional information on the dependence structure. More specifically, we consider the setting where the marginal distributions are known and partial information, in the form of known prices for multi-asset options, is also available in the market. We provide a fundamental theorem of asset pricing in this setting, as well as a superhedging duality that allows to transform the maximization problem over probability measures in a more tractable minimization problem over trading strategies. The latter is solved using a penalization approach combined with a deep learning approximation using artificial neural networks. The numerical method is fast and the computational time scales linearly with respect to the number of traded assets. We finally examine the significance of various pieces of additional information. Empirical evidence suggests that "relevant" information, i.e. prices of derivatives with the same payoff structure as the target payoff, are more useful that other information, and should be prioritized in view of the trade-off between accuracy and computational efficiency.
A time-stepping deep gradient flow method for option pricing in diffusion models
Mar 01, 2024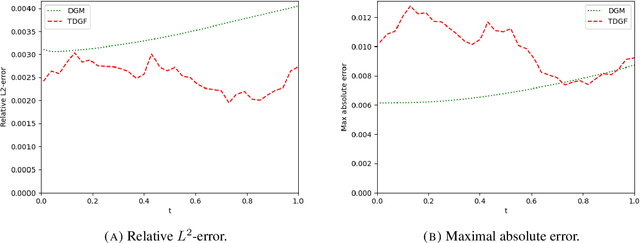

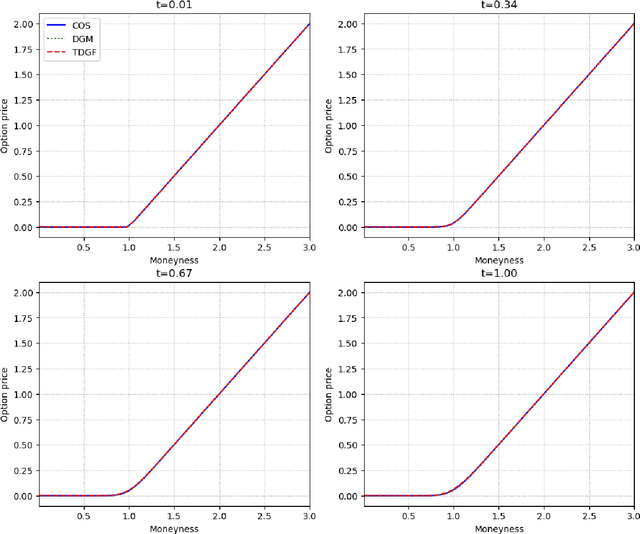
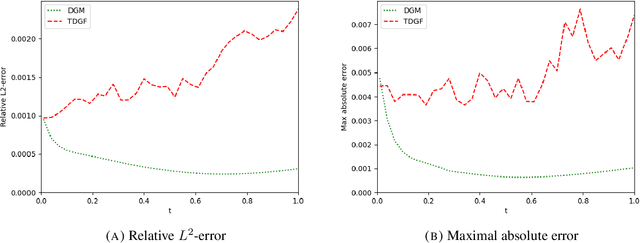
We develop a novel deep learning approach for pricing European options in diffusion models, that can efficiently handle high-dimensional problems resulting from Markovian approximations of rough volatility models. The option pricing partial differential equation is reformulated as an energy minimization problem, which is approximated in a time-stepping fashion by deep artificial neural networks. The proposed scheme respects the asymptotic behavior of option prices for large levels of moneyness, and adheres to a priori known bounds for option prices. The accuracy and efficiency of the proposed method is assessed in a series of numerical examples, with particular focus in the lifted Heston model.
A deep implicit-explicit minimizing movement method for option pricing in jump-diffusion models
Jan 12, 2024



We develop a novel deep learning approach for pricing European basket options written on assets that follow jump-diffusion dynamics. The option pricing problem is formulated as a partial integro-differential equation, which is approximated via a new implicit-explicit minimizing movement time-stepping approach, involving approximation by deep, residual-type Artificial Neural Networks (ANNs) for each time step. The integral operator is discretized via two different approaches: a) a sparse-grid Gauss--Hermite approximation following localised coordinate axes arising from singular value decompositions, and b) an ANN-based high-dimensional special-purpose quadrature rule. Crucially, the proposed ANN is constructed to ensure the asymptotic behavior of the solution for large values of the underlyings and also leads to consistent outputs with respect to a priori known qualitative properties of the solution. The performance and robustness with respect to the dimension of the methods are assessed in a series of numerical experiments involving the Merton jump-diffusion model.
Machine learning for option pricing: an empirical investigation of network architectures
Jul 14, 2023We consider the supervised learning problem of learning the price of an option or the implied volatility given appropriate input data (model parameters) and corresponding output data (option prices or implied volatilities). The majority of articles in this literature considers a (plain) feed forward neural network architecture in order to connect the neurons used for learning the function mapping inputs to outputs. In this article, motivated by methods in image classification and recent advances in machine learning methods for PDEs, we investigate empirically whether and how the choice of network architecture affects the accuracy and training time of a machine learning algorithm. We find that for option pricing problems, where we focus on the Black--Scholes and the Heston model, the generalized highway network architecture outperforms all other variants, when considering the mean squared error and the training time as criteria. Moreover, for the computation of the implied volatility, after a necessary transformation, a variant of the DGM architecture outperforms all other variants, when considering again the mean squared error and the training time as criteria.