 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adaptive Ensembling for Image Classification
Jun 15, 2022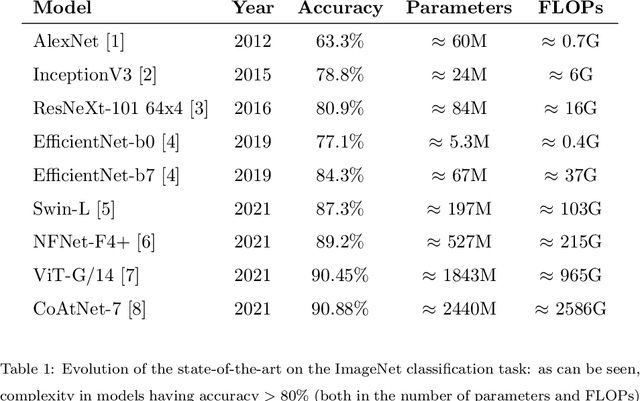
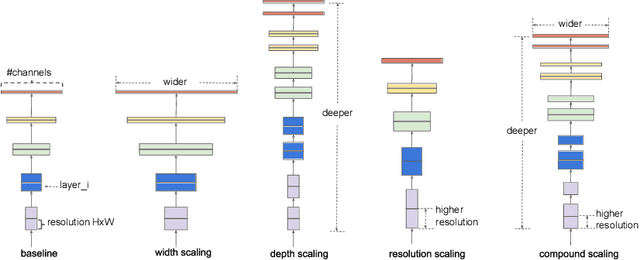
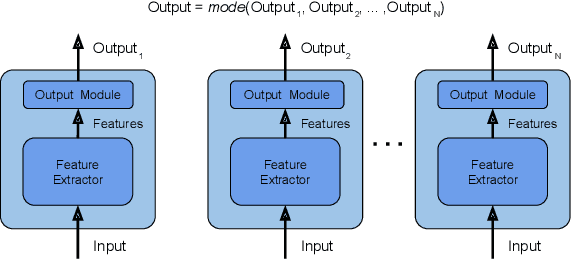
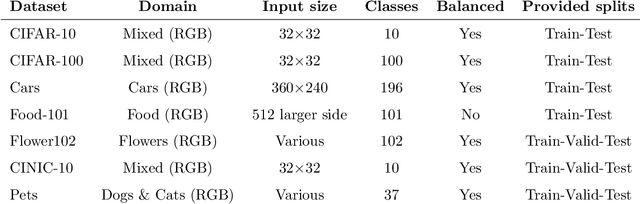
In recent times, except for sporadic cases, the trend in Computer Vision is to achieve minor improvements over considerable increases in complexity. To reverse this tendency, we propose a novel method to boost image classification performances without an increase in complexity. To this end, we revisited ensembling, a powerful approach, not often adequately used due to its nature of increased complexity and training time, making it viable by specific design choices. First, we trained end-to-end two EfficientNet-b0 models (known to be the architecture with the best overall accuracy/complexity trade-off in image classification) on disjoint subsets of data (i.e. bagging). Then, we made an efficient adaptive ensemble by performing fine-tuning of a trainable combination layer. In this way, we were able to outperform the state-of-the-art by an average of 0.5\% on the accuracy with restrained complexity both in terms of number of parameters (by 5-60 times), and FLoating point Operations Per Second (by 10-100 times) on several major benchmark datasets, fully embracing the green AI.
Deep Tree Transductions - A Short Survey
Feb 05, 2019

The paper surveys recent extensions of the Long-Short Term Memory networks to handle tree structures from the perspective of learning non-trivial forms of isomorph structured transductions. It provides a discussion of modern TreeLSTM models, showing the effect of the bias induced by the direction of tree processing. An empirical analysis is performed on real-world benchmarks, highlighting how there is no single model adequate to effectively approach all transduction problems.
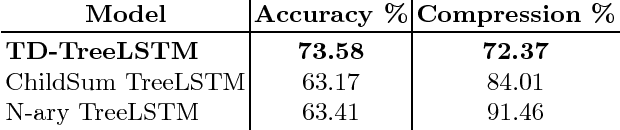
Text Summarization as Tree Transduction by Top-Down TreeLSTM
Sep 24, 2018



Extractive compression is a challenging natural language processing problem. This work contributes by formulating neural extractive compression as a parse tree transduction problem, rather than a sequence transduction task. Motivated by this, we introduce a deep neural model for learning structure-to-substructure tree transductions by extending the standard Long Short-Term Memory, considering the parent-child relationships in the structural recursion. The proposed model can achieve state of the art performance on sentence compression benchmarks, both in terms of accuracy and compression rate.