 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOil reservoir recovery factor assessment using Bayesian networks based on advanced approaches to analogues clustering
Apr 01, 2022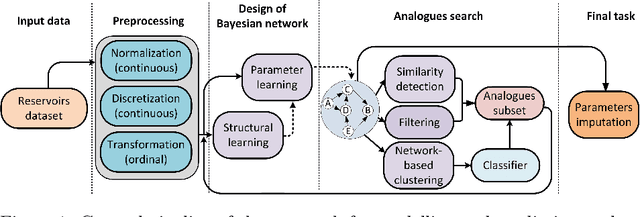
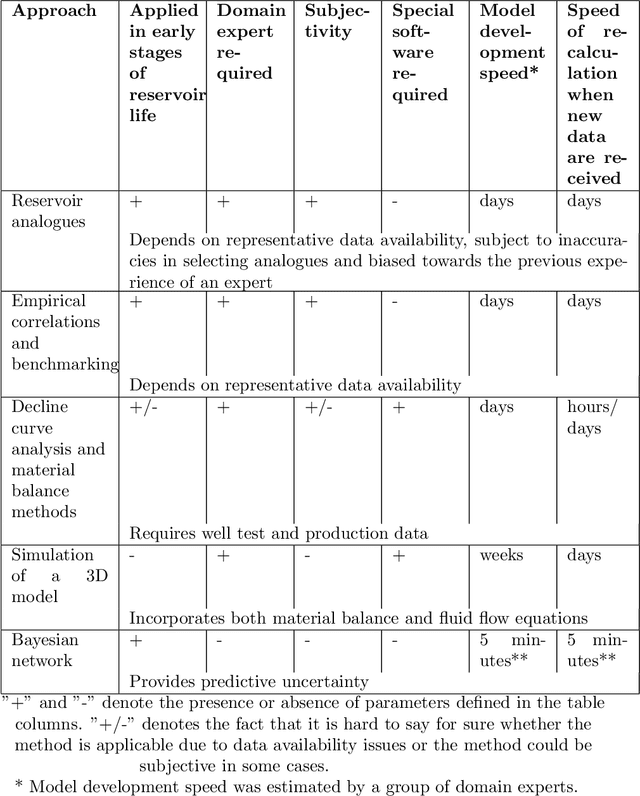
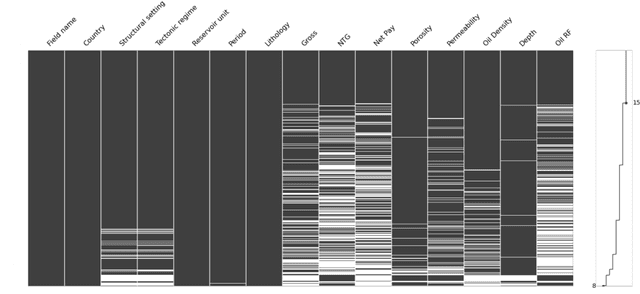
The work focuses on the modelling and imputation of oil and gas reservoirs parameters, specifically, the problem of predicting the oil recovery factor (RF) using Bayesian networks (BNs). Recovery forecasting is critical for the oil and gas industry as it directly affects a company's profit. However, current approaches to forecasting the RF are complex and computationally expensive. In addition, they require vast amount of data and are difficult to constrain in the early stages of reservoir development. To address this problem, we propose a BN approach and describe ways to improve parameter predictions' accuracy. Various training hyperparameters for BNs were considered, and the best ones were used. The approaches of structure and parameter learning, data discretization and normalization, subsampling on analogues of the target reservoir, clustering of networks and data filtering were considered. Finally, a physical model of a synthetic oil reservoir was used to validate BNs' predictions of the RF. All approaches to modelling based on BNs provide full coverage of the confidence interval for the RF predicted by the physical model, but at the same time require less time and data for modelling, which demonstrates the possibility of using in the early stages of reservoirs development. The main result of the work can be considered the development of a methodology for studying the parameters of reservoirs based on Bayesian networks built on small amounts of data and with minimal involvement of expert knowledge. The methodology was tested on the example of the problem of the recovery factor imputation.
Oil and Gas Reservoirs Parameters Analysis Using Mixed Learning of Bayesian Networks
Mar 02, 2021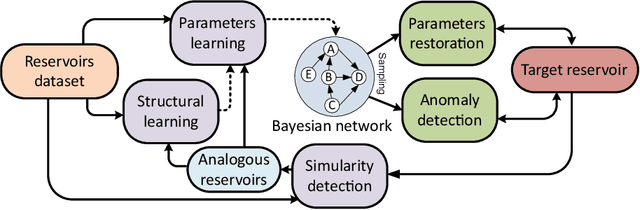
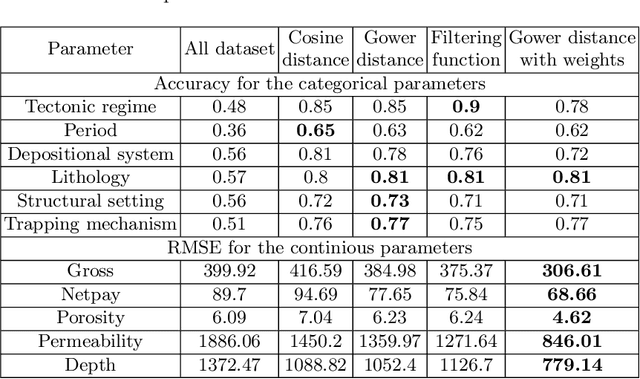
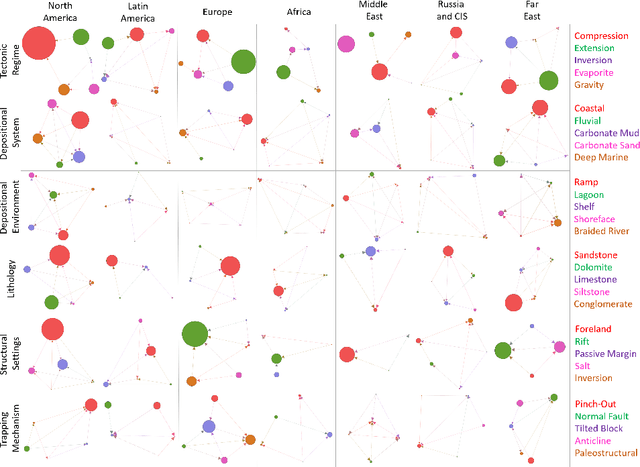
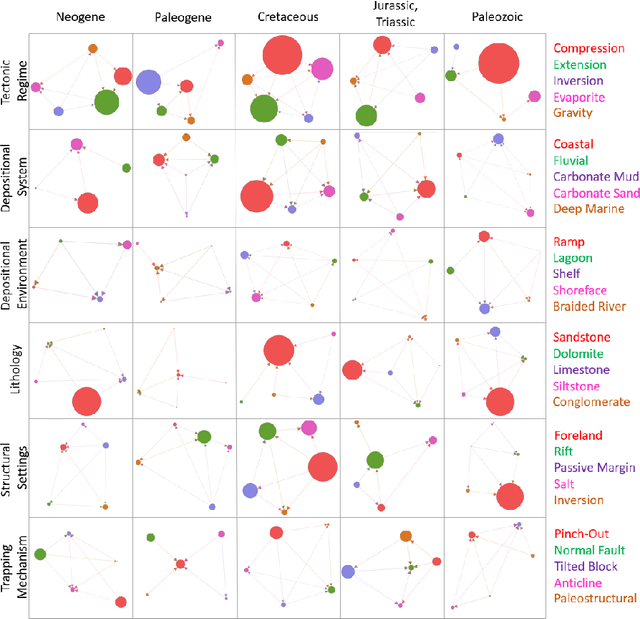
In this paper, a multipurpose Bayesian-based method for data analysis, causal inference and prediction in the sphere of oil and gas reservoir development is considered. This allows analysing parameters of a reservoir, discovery dependencies among parameters (including cause and effects relations), checking for anomalies, prediction of expected values of missing parameters, looking for the closest analogues, and much more. The method is based on extended algorithm MixLearn@BN for structural learning of Bayesian networks. Key ideas of MixLearn@BN are following: (1) learning the network structure on homogeneous data subsets, (2) assigning a part of the structure by an expert, and (3) learning the distribution parameters on mixed data (discrete and continuous). Homogeneous data subsets are identified as various groups of reservoirs with similar features (analogues), where similarity measure may be based on several types of distances. The aim of the described technique of Bayesian network learning is to improve the quality of predictions and causal inference on such networks. Experimental studies prove that the suggested method gives a significant advantage in missing values prediction and anomalies detection accuracy. Moreover, the method was applied to the database of more than a thousand petroleum reservoirs across the globe and allowed to discover novel insights in geological parameters relationships.