 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Straight-Through gradients and Soft-Thresholding all you need for Sparse Training?
Dec 02, 2022



Turning the weights to zero when training a neural network helps in reducing the computational complexity at inference. To progressively increase the sparsity ratio in the network without causing sharp weight discontinuities during training, our work combines soft-thresholding and straight-through gradient estimation to update the raw, i.e. non-thresholded, version of zeroed weights. Our method, named ST-3 for straight-through/soft-thresholding/sparse-training, obtains SoA results, both in terms of accuracy/sparsity and accuracy/FLOPS trade-offs, when progressively increasing the sparsity ratio in a single training cycle. In particular, despite its simplicity, ST-3 favorably compares to the most recent methods, adopting differentiable formulations or bio-inspired neuroregeneration principles. This suggests that the key ingredients for effective sparsification primarily lie in the ability to give the weights the freedom to evolve smoothly across the zero state while progressively increasing the sparsity ratio. Source code and weights available at https://github.com/vanderschuea/stthree
How semantic and geometric information mutually reinforce each other in ToF object localization
Aug 27, 2020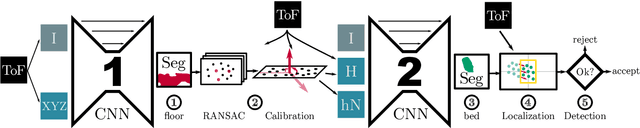

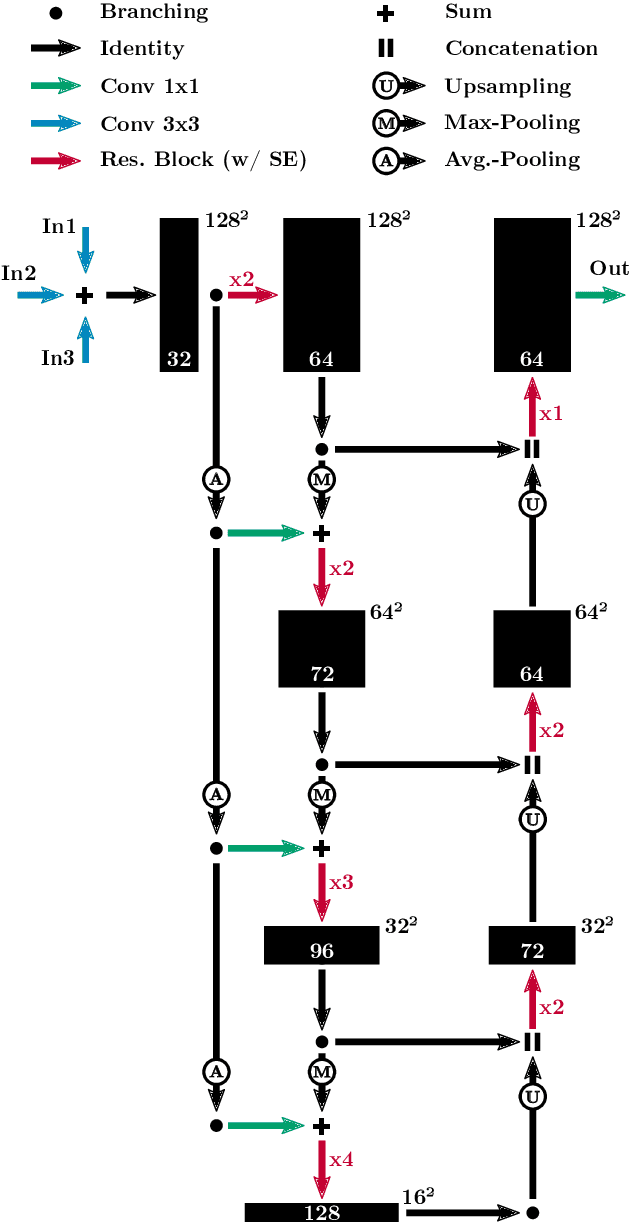
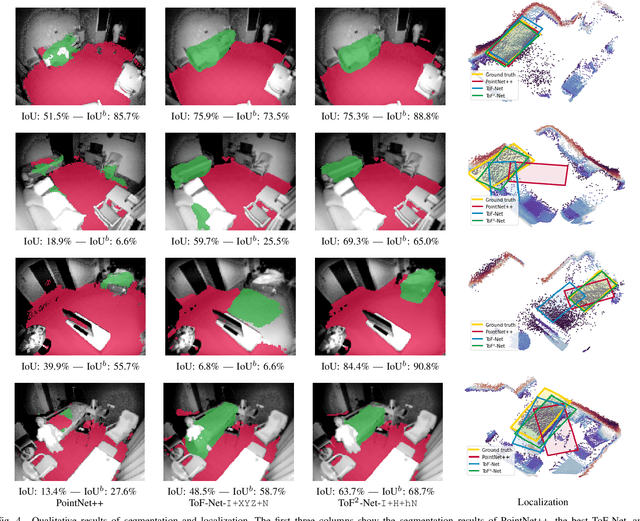
We propose a novel approach to localize a 3D object from the intensity and depth information images provided by a Time-of-Flight (ToF) sensor. Our method uses two CNNs. The first one uses raw depth and intensity images as input, to segment the floor pixels, from which the extrinsic parameters of the camera are estimated. The second CNN is in charge of segmenting the object-of-interest. As a main innovation, it exploits the calibration estimated from the prediction of the first CNN to represent the geometric depth information in a coordinate system that is attached to the ground, and is thus independent of the camera elevation. In practice, both the height of pixels with respect to the ground, and the orientation of normals to the point cloud are provided as input to the second CNN. Given the segmentation predicted by the second CNN, the object is localized based on point cloud alignment with a reference model. Our experiments demonstrate that our proposed two-step approach improves segmentation and localization accuracy by a significant margin compared to a conventional CNN architecture, ignoring calibration and height maps, but also compared to PointNet++.