 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor attacks on DNN and GBDT -- A Case Study from the insurance domain
Dec 11, 2024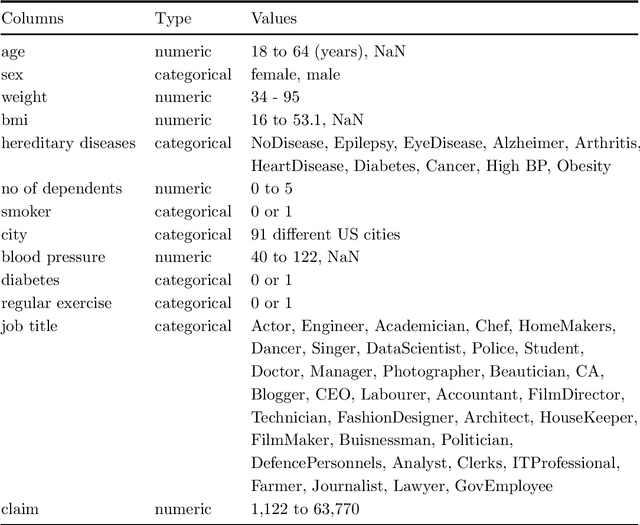
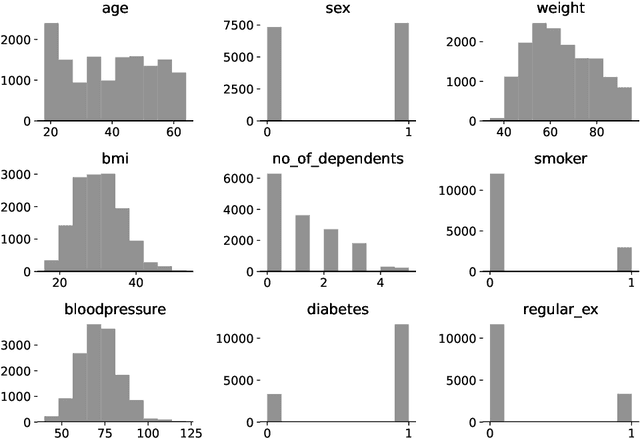
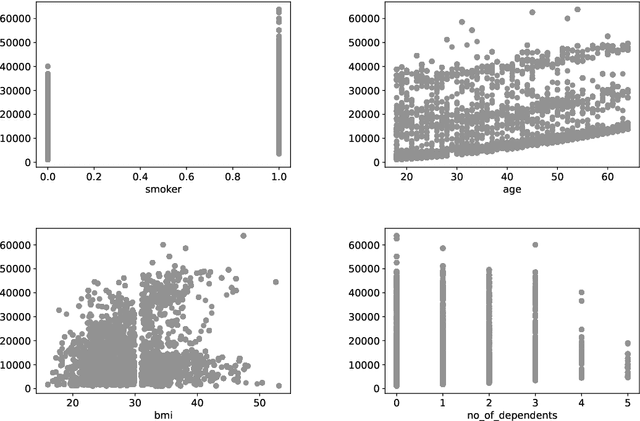

Machine learning (ML) will likely play a large role in many processes in the future, also for insurance companies. However, ML models are at risk of being attacked and manipulated. In this work, the robustness of Gradient Boosted Decision Tree (GBDT) models and Deep Neural Networks (DNN) within an insurance context will be evaluated. Therefore, two GBDT models and two DNNs are trained on two different tabular datasets from an insurance context. Past research in this domain mainly used homogenous data and there are comparably few insights regarding heterogenous tabular data. The ML tasks performed on the datasets are claim prediction (regression) and fraud detection (binary classification). For the backdoor attacks different samples containing a specific pattern were crafted and added to the training data. It is shown, that this type of attack can be highly successful, even with a few added samples. The backdoor attacks worked well on the models trained on one dataset but poorly on the models trained on the other. In real-world scenarios the attacker will have to face several obstacles but as attacks can work with very few added samples this risk should be evaluated.
Training Gradient Boosted Decision Trees on Tabular Data Containing Label Noise for Classification Tasks
Sep 13, 2024Label noise refers to the phenomenon where instances in a data set are assigned to the wrong label. Label noise is harmful to classifier performance, increases model complexity and impairs feature selection. Addressing label noise is crucial, yet current research primarily focuses on image and text data using deep neural networks. This leaves a gap in the study of tabular data and gradient-boosted decision trees (GBDTs), the leading algorithm for tabular data. Different methods have already been developed which either try to filter label noise, model label noise while simultaneously training a classifier or use learning algorithms which remain effective even if label noise is present. This study aims to further investigate the effects of label noise on gradient-boosted decision trees and methods to mitigate those effects. Through comprehensive experiments and analysis, the implemented methods demonstrate state-of-the-art noise detection performance on the Adult dataset and achieve the highest classification precision and recall on the Adult and Breast Cancer datasets, respectively. In summary, this paper enhances the understanding of the impact of label noise on GBDTs and lays the groundwork for future research in noise detection and correction methods.