 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicography Saves Lives (LSL): Automatically Translating Suicide-Related Language
Dec 20, 2024Recent years have seen a marked increase in research that aims to identify or predict risk, intention or ideation of suicide. The majority of new tasks, datasets, language models and other resources focus on English and on suicide in the context of Western culture. However, suicide is global issue and reducing suicide rate by 2030 is one of the key goals of the UN's Sustainable Development Goals. Previous work has used English dictionaries related to suicide to translate into different target languages due to lack of other available resources. Naturally, this leads to a variety of ethical tensions (e.g.: linguistic misrepresentation), where discourse around suicide is not present in a particular culture or country. In this work, we introduce the 'Lexicography Saves Lives Project' to address this issue and make three distinct contributions. First, we outline ethical consideration and provide overview guidelines to mitigate harm in developing suicide-related resources. Next, we translate an existing dictionary related to suicidal ideation into 200 different languages and conduct human evaluations on a subset of translated dictionaries. Finally, we introduce a public website to make our resources available and enable community participation.
MEANT: Multimodal Encoder for Antecedent Information
Nov 10, 2024

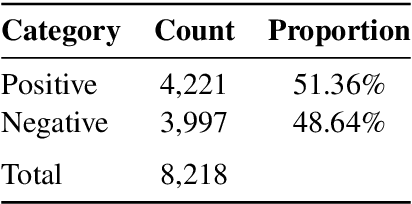

The stock market provides a rich well of information that can be split across modalities, making it an ideal candidate for multimodal evaluation. Multimodal data plays an increasingly important role in the development of machine learning and has shown to positively impact performance. But information can do more than exist across modes -- it can exist across time. How should we attend to temporal data that consists of multiple information types? This work introduces (i) the MEANT model, a Multimodal Encoder for Antecedent information and (ii) a new dataset called TempStock, which consists of price, Tweets, and graphical data with over a million Tweets from all of the companies in the S&P 500 Index. We find that MEANT improves performance on existing baselines by over 15%, and that the textual information affects performance far more than the visual information on our time-dependent task from our ablation study.