 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised vision-langage alignment of deep learning representations for bone X-rays analysis
May 14, 2024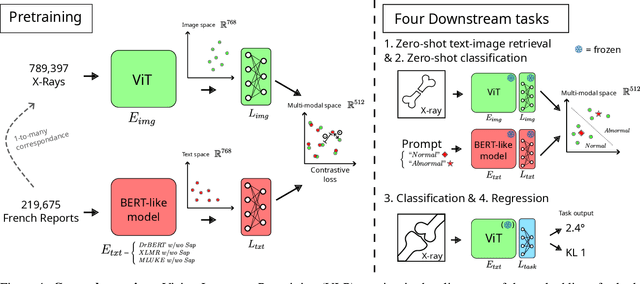



This paper proposes leveraging vision-language pretraining on bone X-rays paired with French reports to address downstream tasks of interest on bone radiography. A practical processing pipeline is introduced to anonymize and process French medical reports. Pretraining then consists in the self-supervised alignment of visual and textual embedding spaces derived from deep model encoders. The resulting image encoder is then used to handle various downstream tasks, including quantification of osteoarthritis, estimation of bone age on pediatric wrists, bone fracture and anomaly detection. Our approach demonstrates competitive performance on downstream tasks, compared to alternatives requiring a significantly larger amount of human expert annotations. Our work stands as the first study to integrate French reports to shape the embedding space devoted to bone X-Rays representations, capitalizing on the large quantity of paired images and reports data available in an hospital. By relying on generic vision-laguage deep models in a language-specific scenario, it contributes to the deployement of vision models for wider healthcare applications.
Improved anomaly detection by training an autoencoder with skip connections on images corrupted with Stain-shaped noise
Aug 29, 2020
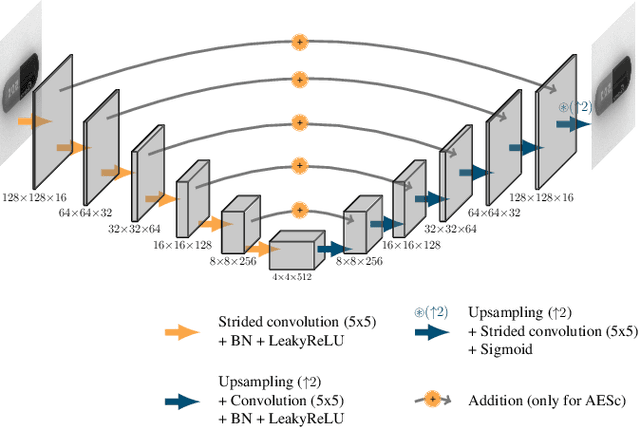


In industrial vision, the anomaly detection problem can be addressed with an autoencoder trained to map an arbitrary image, i.e. with or without any defect, to a clean image, i.e. without any defect. In this approach, anomaly detection relies conventionally on the reconstruction residual or, alternatively, on the reconstruction uncertainty. To improve the sharpness of the reconstruction, we consider an autoencoder architecture with skip connections. In the common scenario where only clean images are available for training, we propose to corrupt them with a synthetic noise model to prevent the convergence of the network towards the identity mapping, and introduce an original Stain noise model for that purpose. We show that this model favors the reconstruction of clean images from arbitrary real-world images, regardless of the actual defects appearance. In addition to demonstrating the relevance of our approach, our validation provides the first consistent assessment of reconstruction-based methods, by comparing their performance over the MVTec AD dataset, both for pixel- and image-wise anomaly detection.