 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Stochastic Gaussian Process Latent Variable Models: A Multi-modal Generative Model for Quasar Spectra
Feb 27, 2025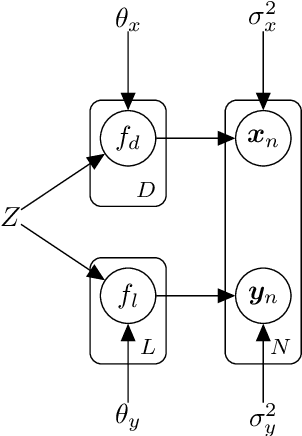
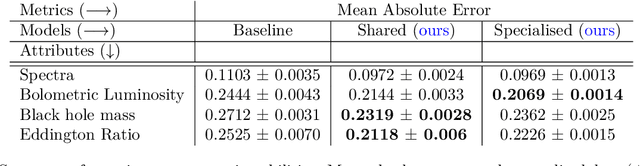
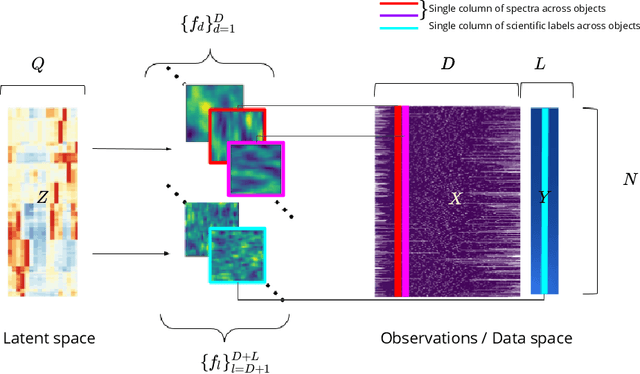
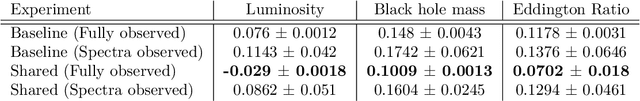
This work proposes a scalable probabilistic latent variable model based on Gaussian processes (Lawrence, 2004) in the context of multiple observation spaces. We focus on an application in astrophysics where data sets typically contain both observed spectral features and scientific properties of astrophysical objects such as galaxies or exoplanets. In our application, we study the spectra of very luminous galaxies known as quasars, along with their properties, such as the mass of their central supermassive black hole, accretion rate, and luminosity-resulting in multiple observation spaces. A single data point is then characterized by different classes of observations, each with different likelihoods. Our proposed model extends the baseline stochastic variational Gaussian process latent variable model (GPLVM) introduced by Lalchand et al. (2022) to this setting, proposing a seamless generative model where the quasar spectra and scientific labels can be generated simultaneously using a shared latent space as input to different sets of Gaussian process decoders, one for each observation space. Additionally, this framework enables training in a missing data setting where a large number of dimensions per data point may be unknown or unobserved. We demonstrate high-fidelity reconstructions of the spectra and scientific labels during test-time inference and briefly discuss the scientific interpretations of the results, along with the significance of such a generative model.
* Published in TMLR, https://openreview.net/pdf?id=LzmsvRTqaJ. The code for this work is available at: https://github.com/vr308/Quasar-GPLVM
Streamlined Lensed Quasar Identification in Multiband Images via Ensemble Networks
Jul 03, 2023



Quasars experiencing strong lensing offer unique viewpoints on subjects like the cosmic expansion rate, the dark matter profile within the foreground deflectors, and the quasar host galaxies. Unfortunately, identifying them in astronomical images is challenging since they are overwhelmed by the abundance of non-lenses. To address this, we have developed a novel approach by ensembling cutting-edge convolutional networks (CNNs) -- i.e., ResNet, Inception, NASNet, MobileNet, EfficientNet, and RegNet -- along with vision transformers (ViTs) trained on realistic galaxy-quasar lens simulations based on the Hyper Suprime-Cam (HSC) multiband images. While the individual model exhibits remarkable performance when evaluated against the test dataset, achieving an area under the receiver operating characteristic curve of $>$97.4% and a median false positive rate of 3.1%, it struggles to generalize in real data, indicated by numerous spurious sources picked by each classifier. A significant improvement is achieved by averaging these CNNs and ViTs, resulting in the impurities being downsized by factors up to 40. Subsequently, combining the HSC images with the UKIRT, VISTA, and unWISE data, we retrieve approximately 60 million sources as parent samples and reduce this to 892,609 after employing a photometry preselection to discover $z>1.5$ lensed quasars with Einstein radii of $\theta_\mathrm{E}<5$ arcsec. Afterward, the ensemble classifier indicates 3991 sources with a high probability of being lenses, for which we visually inspect, yielding 161 prevailing candidates awaiting spectroscopic confirmation. These outcomes suggest that automated deep learning pipelines hold great potential in effectively detecting strong lenses in vast datasets with minimal manual visual inspection involved.
When Spectral Modeling Meets Convolutional Networks: A Method for Discovering Reionization-era Lensed Quasars in Multi-band Imaging Data
Nov 26, 2022Over the last two decades, around three hundred quasars have been discovered at $z\gtrsim6$, yet only one was identified as being strong-gravitationally lensed. We explore a new approach, enlarging the permitted spectral parameter space while introducing a new spatial geometry veto criterion, implemented via image-based deep learning. We made the first application of this approach in a systematic search for reionization-era lensed quasars, using data from the Dark Energy Survey, the Visible and Infrared Survey Telescope for Astronomy Hemisphere Survey, and the Wide-field Infrared Survey Explorer. Our search method consists of two main parts: (i) pre-selection of the candidates based on their spectral energy distributions (SEDs) using catalog-level photometry and (ii) relative probabilities calculation of being a lens or some contaminant utilizing a convolutional neural network (CNN) classification. The training datasets are constructed by painting deflected point-source lights over actual galaxy images to generate realistic galaxy-quasar lens models, optimized to find systems with small image separations, i.e., Einstein radii of $\theta_\mathrm{E} \leq 1$ arcsec. Visual inspection is then performed for sources with CNN scores of $P_\mathrm{lens} > 0.1$, which led us to obtain 36 newly-selected lens candidates, waiting for spectroscopic confirmation. These findings show that automated SED modeling and deep learning pipelines, supported by modest human input, are a promising route for detecting strong lenses from large catalogs that can overcome the veto limitations of primarily dropout-based SED selection approaches.