 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study of feature selection methods for stress hotspot classification in materials
Apr 19, 2018
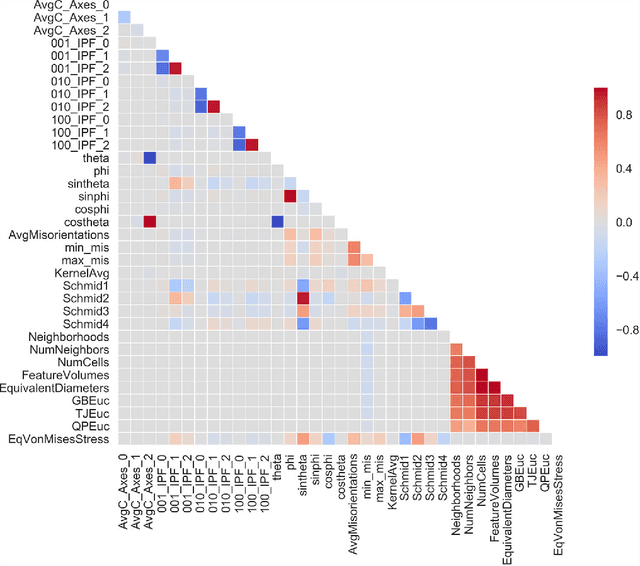
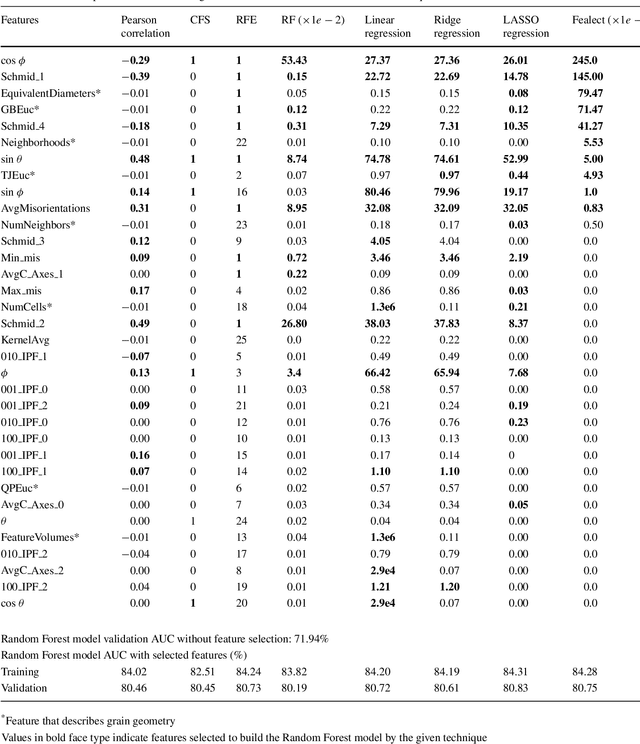
The first step in constructing a machine learning model is defining the features of the data set that can be used for optimal learning. In this work we discuss feature selection methods, which can be used to build better models, as well as achieve model interpretability. We applied these methods in the context of stress hotspot classification problem, to determine what microstructural characteristics can cause stress to build up in certain grains during uniaxial tensile deformation. The results show how some feature selection techniques are biased and demonstrate a preferred technique to get feature rankings for physical interpretations.
Using Big Data to Enhance the Bosch Production Line Performance: A Kaggle Challenge
Dec 29, 2016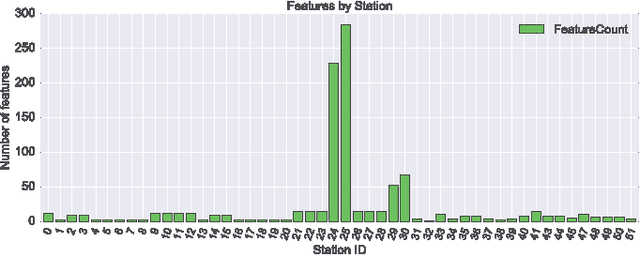
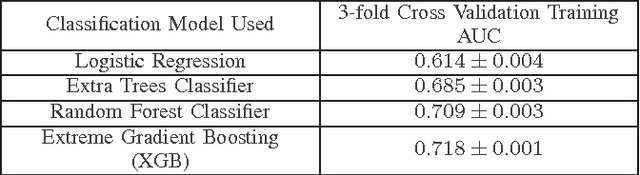
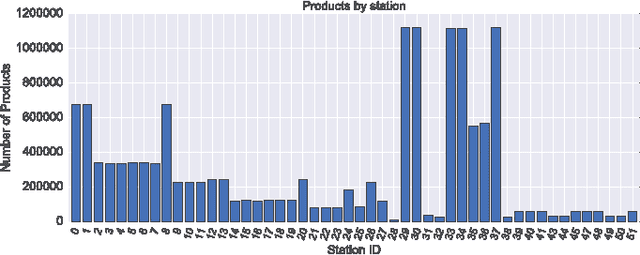
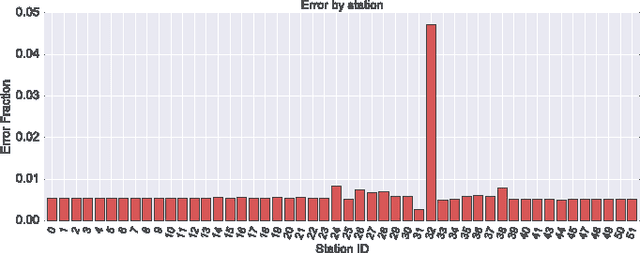
This paper describes our approach to the Bosch production line performance challenge run by Kaggle.com. Maximizing the production yield is at the heart of the manufacturing industry. At the Bosch assembly line, data is recorded for products as they progress through each stage. Data science methods are applied to this huge data repository consisting records of tests and measurements made for each component along the assembly line to predict internal failures. We found that it is possible to train a model that predicts which parts are most likely to fail. Thus a smarter failure detection system can be built and the parts tagged likely to fail can be salvaged to decrease operating costs and increase the profit margins.