 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel ASIC Design Flow using Weight-Tunable Binary Neurons as Standard Cells
Apr 17, 2022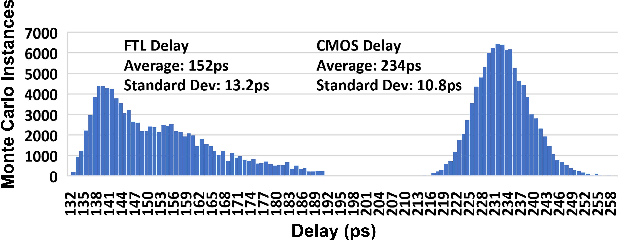
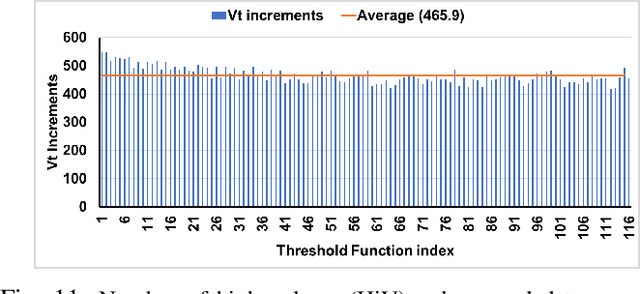
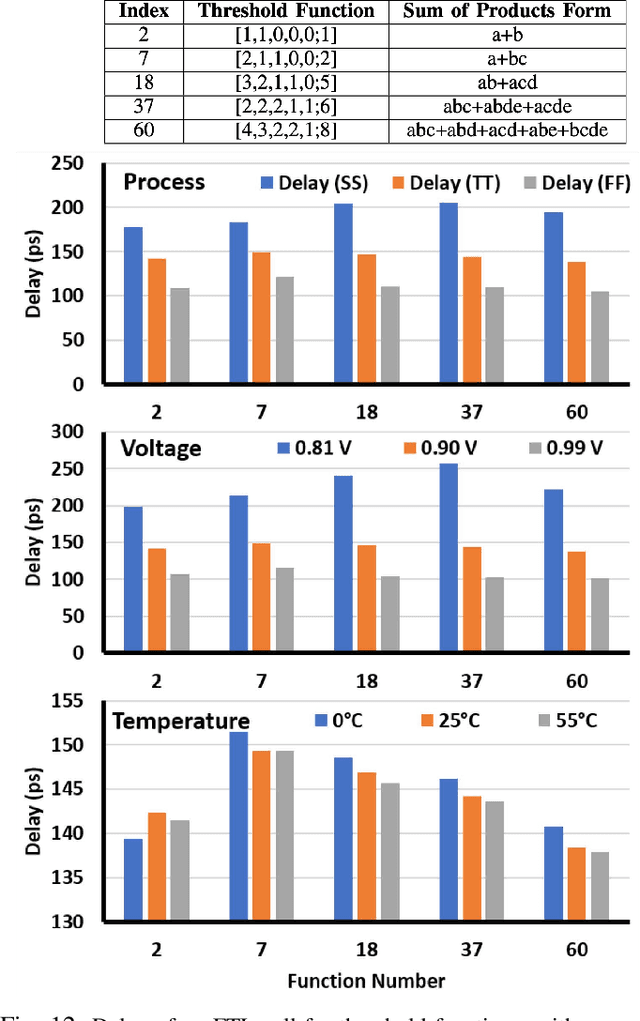
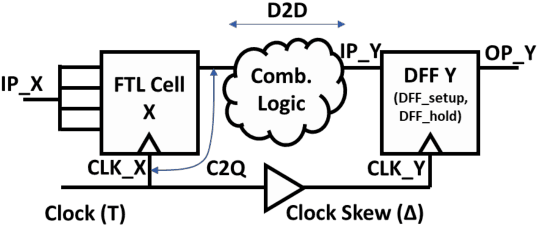
In this paper, we describe a design of a mixed signal circuit for a binary neuron (a.k.a perceptron, threshold logic gate) and a methodology for automatically embedding such cells in ASICs. The binary neuron, referred to as an FTL (flash threshold logic) uses floating gate or flash transistors whose threshold voltages serve as a proxy for the weights of the neuron. Algorithms for mapping the weights to the flash transistor threshold voltages are presented. The threshold voltages are determined to maximize both the robustness of the cell and its speed. The performance, power, and area of a single FTL cell are shown to be significantly smaller (79.4%), consume less power (61.6%), and operate faster (40.3%) compared to conventional CMOS logic equivalents. Also included are the architecture and the algorithms to program the flash devices of an FTL. The FTL cells are implemented as standard cells, and are designed to allow commercial synthesis and P&R tools to automatically use them in synthesis of ASICs. Substantial reductions in area and power without sacrificing performance are demonstrated on several ASIC benchmarks by the automatic embedding of FTL cells. The paper also demonstrates how FTL cells can be used for fixing timing errors after fabrication.
A Configurable BNN ASIC using a Network of Programmable Threshold Logic Standard Cells
Apr 04, 2021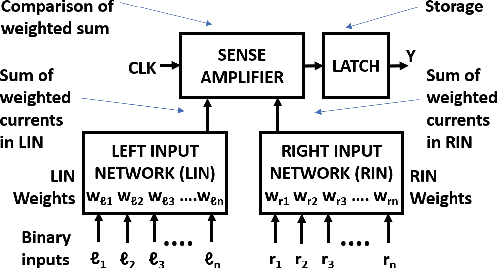
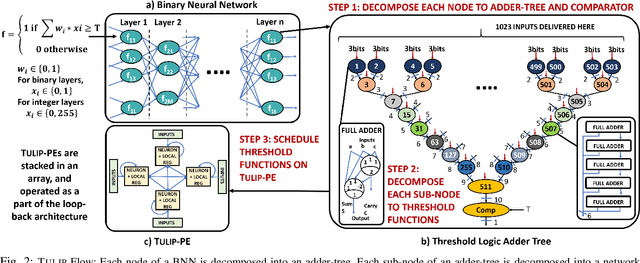
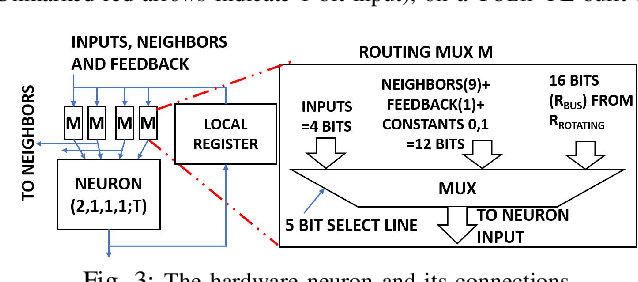
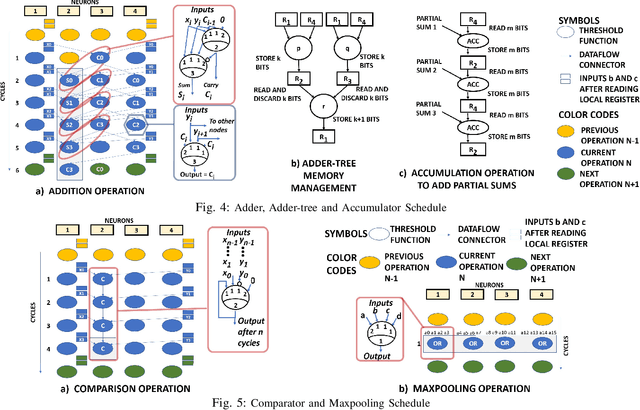
This paper presents TULIP, a new architecture for a binary neural network (BNN) that uses an optimal schedule for executing the operations of an arbitrary BNN. It was constructed with the goal of maximizing energy efficiency per classification. At the top-level, TULIP consists of a collection of unique processing elements (TULIP-PEs) that are organized in a SIMD fashion. Each TULIP-PE consists of a small network of binary neurons, and a small amount of local memory per neuron. The unique aspect of the binary neuron is that it is implemented as a mixed-signal circuit that natively performs the inner-product and thresholding operation of an artificial binary neuron. Moreover, the binary neuron, which is implemented as a single CMOS standard cell, is reconfigurable, and with a change in a single parameter, can implement all standard operations involved in a BNN. We present novel algorithms for mapping arbitrary nodes of a BNN onto the TULIP-PEs. TULIP was implemented as an ASIC in TSMC 40nm-LP technology. To provide a fair comparison, a recently reported BNN that employs a conventional MAC-based arithmetic processor was also implemented in the same technology. The results show that TULIP is consistently 3X more energy-efficient than the conventional design, without any penalty in performance, area, or accuracy.