 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompAdaGrad: A Compressed, Complementary, Computationally-Efficient Adaptive Gradient Method
Oct 04, 2016
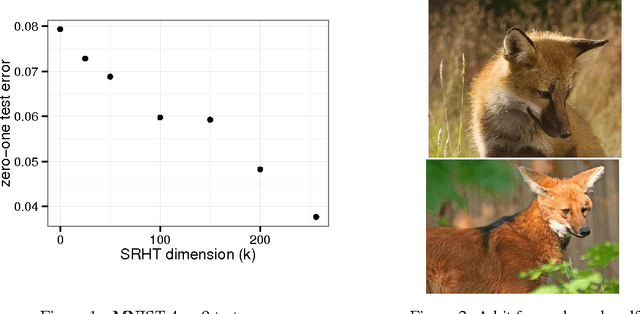
The adaptive gradient online learning method known as AdaGrad has seen widespread use in the machine learning community in stochastic and adversarial online learning problems and more recently in deep learning methods. The method's full-matrix incarnation offers much better theoretical guarantees and potentially better empirical performance than its diagonal version; however, this version is computationally prohibitive and so the simpler diagonal version often is used in practice. We introduce a new method, CompAdaGrad, that navigates the space between these two schemes and show that this method can yield results much better than diagonal AdaGrad while avoiding the (effectively intractable) $O(n^3)$ computational complexity of full-matrix AdaGrad for dimension $n$. CompAdaGrad essentially performs full-matrix regularization in a low-dimensional subspace while performing diagonal regularization in the complementary subspace. We derive CompAdaGrad's updates for composite mirror descent in case of the squared $\ell_2$ norm and the $\ell_1$ norm, demonstrate that its complexity per iteration is linear in the dimension, and establish guarantees for the method independent of the choice of composite regularizer. Finally, we show preliminary results on several datasets.