 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Landscape of Generative AI in Information Systems: A Synthesis of Secondary Reviews and Research Agendas
Mar 12, 2026As organizations grapple with the rapid adoption of Generative AI (GenAI), this study synthesizes the state of knowledge through a systematic literature review of secondary studies and research agendas. Analyzing 28 papers published since 2023, we find that while GenAI offers transformative potential for productivity and innovation, its adoption is constrained by multiple interrelated challenges, including technical unreliability (hallucinations, performance drift), societal-ethical risks (bias, misuse, skill erosion), and a systemic governance vacuum (privacy, accountability, intellectual property). Interpreted through a socio-technical lens, these findings reveal a persistent misalignment between GenAI's fast-evolving technical subsystem and the slower-adapting social subsystem, positioning IS research as critical for achieving joint optimization. To bridge this gap, we discuss a research agenda that reorients IS scholarship from analyzing impacts toward actively shaping the co-evolution of technical capabilities with organizational procedures, societal values, and regulatory institutions--emphasizing hybrid human--AI ensembles, situated validation, design principles for probabilistic systems, and adaptive governance.
FAIREDU: A Multiple Regression-Based Method for Enhancing Fairness in Machine Learning Models for Educational Applications
Oct 08, 2024Fairness in artificial intelligence and machine learning (AI/ML) models is becoming critically important, especially as decisions made by these systems impact diverse groups. In education, a vital sector for all countries, the widespread application of AI/ML systems raises specific concerns regarding fairness. Current research predominantly focuses on fairness for individual sensitive features, which limits the comprehensiveness of fairness assessments. This paper introduces FAIREDU, a novel and effective method designed to improve fairness across multiple sensitive features. Through extensive experiments, we evaluate FAIREDU effectiveness in enhancing fairness without compromising model performance. The results demonstrate that FAIREDU addresses intersectionality across features such as gender, race, age, and other sensitive features, outperforming state-of-the-art methods with minimal effect on model accuracy. The paper also explores potential future research directions to enhance further the method robustness and applicability to various machine-learning models and datasets.
An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation
Aug 28, 2024Large Language Models (LLMs) have recently advanced many applications on software engineering tasks, particularly the potential for code generation. Among contemporary challenges, code generated by LLMs often suffers from inaccuracies and hallucinations, requiring external inputs to correct. One recent strategy to fix these issues is to refine the code generated from LLMs using the input from the model itself (self-augmented). In this work, we proposed a novel method, namely CoT-SelfEvolve. CoT-SelfEvolve iteratively and automatically refines code through a self-correcting process, guided by a chain of thought constructed from real-world programming problem feedback. Focusing on data science code, including Python libraries such as NumPy and Pandas, our evaluations on the DS-1000 dataset demonstrate that CoT-SelfEvolve significantly outperforms existing models in solving complex problems. The framework shows substantial improvements in both initial code generation and subsequent iterations, with the model's accuracy increasing significantly with each additional iteration. This highlights the effectiveness of using chain-of-thought prompting to address complexities revealed by program executor traceback error messages. We also discuss how CoT-SelfEvolve can be integrated into continuous software engineering environments, providing a practical solution for improving LLM-based code generation.
Software engineering for artificial intelligence and machine learning software: A systematic literature review
Nov 07, 2020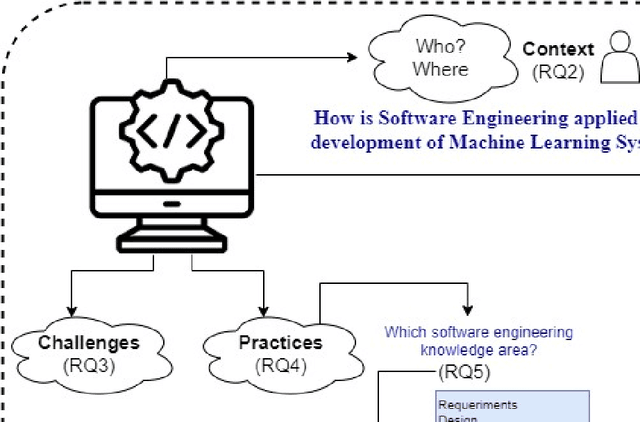
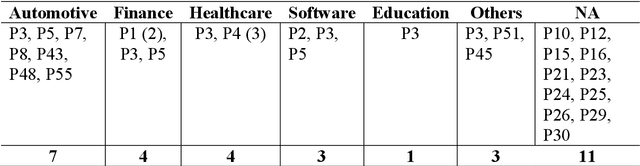
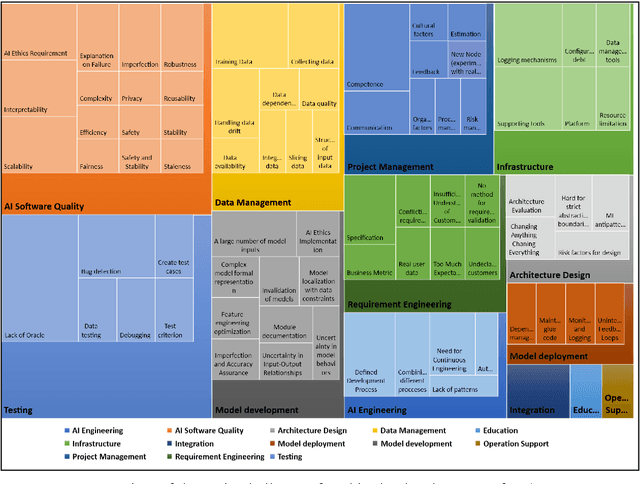

Artificial Intelligence (AI) or Machine Learning (ML) systems have been widely adopted as value propositions by companies in all industries in order to create or extend the services and products they offer. However, developing AI/ML systems has presented several engineering problems that are different from those that arise in, non-AI/ML software development. This study aims to investigate how software engineering (SE) has been applied in the development of AI/ML systems and identify challenges and practices that are applicable and determine whether they meet the needs of professionals. Also, we assessed whether these SE practices apply to different contexts, and in which areas they may be applicable. We conducted a systematic review of literature from 1990 to 2019 to (i) understand and summarize the current state of the art in this field and (ii) analyze its limitations and open challenges that will drive future research. Our results show these systems are developed on a lab context or a large company and followed a research-driven development process. The main challenges faced by professionals are in areas of testing, AI software quality, and data management. The contribution types of most of the proposed SE practices are guidelines, lessons learned, and tools.