 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Contain Multitudes: How Deployment Context Reshapes Model-Level Preferences and Values
Jun 11, 2026Large language models (LLMs) are increasingly characterised in recent evaluation work as having stable, model-level preference and value systems. However, accompanying robustness checks are limited to incidental prompt perturbations such as syntax variation and option reordering. This leaves open whether the measured properties survive when the surrounding task context changes, as it does in most real deployments. We test this directly across two established pairwise paradigms: ranking country preferences and eliciting utility judgements. In both, we make the deployment context -- the high-level task the model is performing while making concrete value-dependent choices -- our controlled variable, varied across framings such as writing a Reddit post or a news article. Across five LLMs and over 1.2M pairwise decisions, deployment context produces variation far larger than prompt paraphrasing and temperature controls. In country preference rankings over 15 countries, context induces widespread, statistically significant rank shifts; the aggregate Global North favouritism reported in prior work is itself context-dependent, with each model's bias shifting systematically across contexts. In utility elicitation over 50 outcomes, broad cross-category ordering is preserved, but fine-grained rankings within domains vary substantially, and cardinal exchange rates between outcomes (e.g. how many lives in one region equal one in another) shift by a factor of 2.47 at the median. Reported model-level preferences and utilities are therefore better understood as context-conditioned measurements than fixed model-level properties: safety guarantees obtained under one framing provide limited assurance in another.
Predicting Drug Interactions and Mutagenicity with Ensemble Classifiers on Subgraphs of Molecules
Jan 27, 2016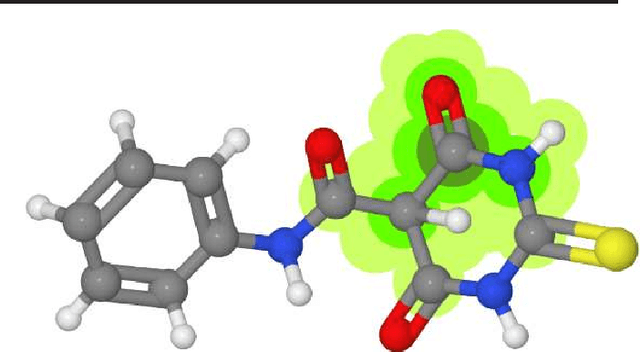

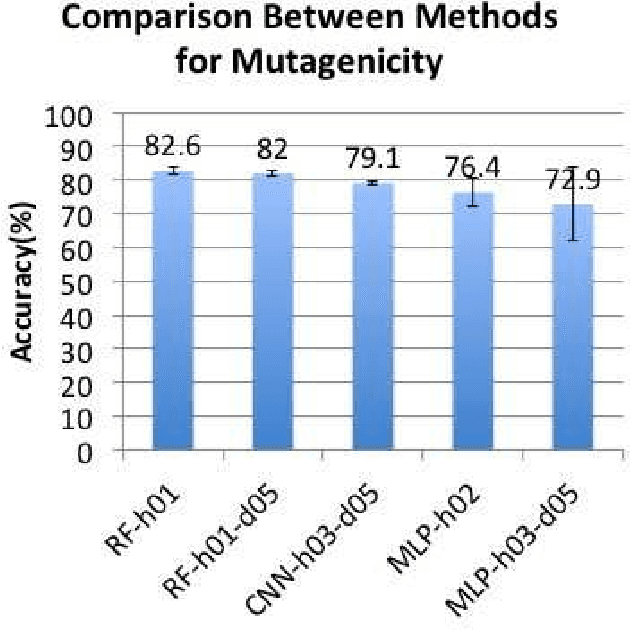
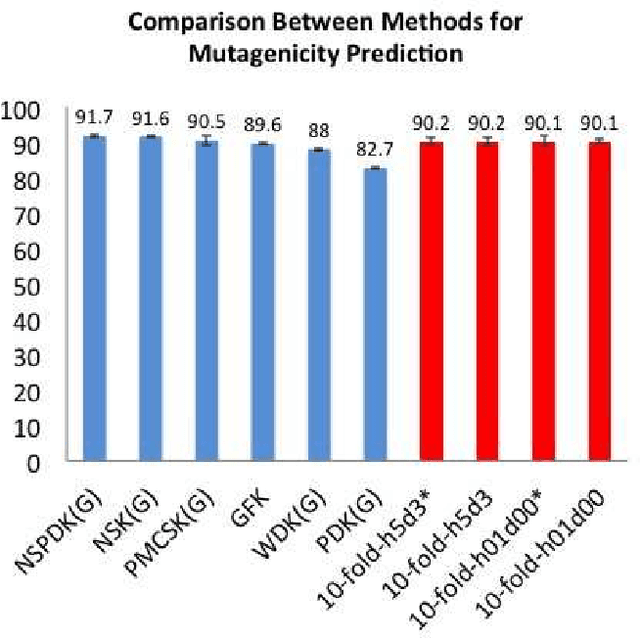
In this study, we intend to solve a mutual information problem in interacting molecules of any type, such as proteins, nucleic acids, and small molecules. Using machine learning techniques, we accurately predict pairwise interactions, which can be of medical and biological importance. Graphs are are useful in this problem for their generality to all types of molecules, due to the inherent association of atoms through atomic bonds. Subgraphs can represent different molecular domains. These domains can be biologically significant as most molecules only have portions that are of functional significance and can interact with other domains. Thus, we use subgraphs as features in different machine learning algorithms to predict if two drugs interact and predict potential single molecule effects.
Active Sensing as Bayes-Optimal Sequential Decision Making
Aug 09, 2014
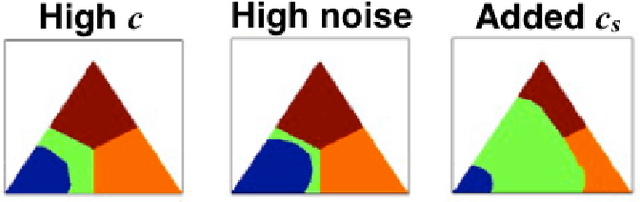
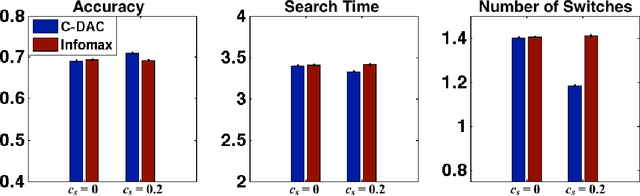
Sensory inference under conditions of uncertainty is a major problem in both machine learning and computational neuroscience. An important but poorly understood aspect of sensory processing is the role of active sensing. Here, we present a Bayes-optimal inference and control framework for active sensing, C-DAC (Context-Dependent Active Controller). Unlike previously proposed algorithms that optimize abstract statistical objectives such as information maximization (Infomax) [Butko & Movellan, 2010] or one-step look-ahead accuracy [Najemnik & Geisler, 2005], our active sensing model directly minimizes a combination of behavioral costs, such as temporal delay, response error, and effort. We simulate these algorithms on a simple visual search task to illustrate scenarios in which context-sensitivity is particularly beneficial and optimization with respect to generic statistical objectives particularly inadequate. Motivated by the geometric properties of the C-DAC policy, we present both parametric and non-parametric approximations, which retain context-sensitivity while significantly reducing computational complexity. These approximations enable us to investigate the more complex problem involving peripheral vision, and we notice that the difference between C-DAC and statistical policies becomes even more evident in this scenario.