 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques for Measuring the Inferential Strength of Forgetting Policies
Apr 07, 2024The technique of forgetting in knowledge representation has been shown to be a powerful and useful knowledge engineering tool with widespread application. Yet, very little research has been done on how different policies of forgetting, or use of different forgetting operators, affects the inferential strength of the original theory. The goal of this paper is to define loss functions for measuring changes in inferential strength based on intuitions from model counting and probability theory. Properties of such loss measures are studied and a pragmatic knowledge engineering tool is proposed for computing loss measures using Problog. The paper includes a working methodology for studying and determining the strength of different forgetting policies, in addition to concrete examples showing how to apply the theoretical results using Problog. Although the focus is on forgetting, the results are much more general and should have wider application to other areas.
Dual Forgetting Operators in the Context of Weakest Sufficient and Strongest Necessary Conditions
May 12, 2023
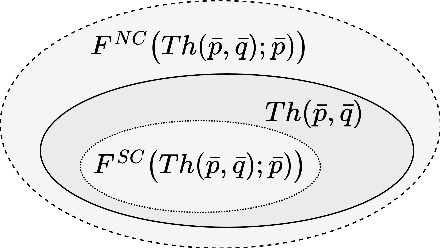
Forgetting is an important concept in knowledge representation and automated reasoning with widespread applications across a number of disciplines. A standard forgetting operator, characterized in [Lin and Reiter'94] in terms of model-theoretic semantics and primarily focusing on the propositional case, opened up a new research subarea. In this paper, a new operator called weak forgetting, dual to standard forgetting, is introduced and both together are shown to offer a new more uniform perspective on forgetting operators in general. Both the weak and standard forgetting operators are characterized in terms of entailment and inference, rather than a model theoretic semantics. This naturally leads to a useful algorithmic perspective based on quantifier elimination and the use of Ackermman's Lemma and its fixpoint generalization. The strong formal relationship between standard forgetting and strongest necessary conditions and weak forgetting and weakest sufficient conditions is also characterized quite naturally through the entailment-based, inferential perspective used. The framework used to characterize the dual forgetting operators is also generalized to the first-order case and includes useful algorithms for computing first-order forgetting operators in special cases. Practical examples are also included to show the importance of both weak and standard forgetting in modeling and representation.
A Paraconsistent ASP-like Language with Tractable Model Generation
Dec 20, 2019



Answer Set Programming (ASP) is nowadays a dominant rule-based knowledge representation tool. Though existing ASP variants enjoy efficient implementations, generating an answer set remains intractable. The goal of this research is to define a new \asp-like rule language, 4SP, with tractable model generation. The language combines ideas of ASP and a paraconsistent rule language 4QL. Though 4SP shares the syntax of \asp and for each program all its answer sets are among 4SP models, the new language differs from ASP in its logical foundations, the intended methodology of its use and complexity of computing models. As we show in the paper, 4QL can be seen as a paraconsistent counterpart of ASP programs stratified with respect to default negation. Although model generation of well-supported models for 4QL programs is tractable, dropping stratification makes both 4QL and ASP intractable. To retain tractability while allowing non-stratified programs, in 4SP we introduce trial expressions interlacing programs with hypotheses as to the truth values of default negations. This allows us to develop a~model generation algorithm with deterministic polynomial time complexity. We also show relationships among 4SP, ASP and 4QL.