 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-Concave Coupling for Sampling Neural Net Posteriors
Jul 26, 2024In this work, we present a sampling algorithm for single hidden layer neural networks. This algorithm is built upon a recursive series of Bayesian posteriors using a method we call Greedy Bayes. Sampling of the Bayesian posterior for neuron weight vectors $w$ of dimension $d$ is challenging because of its multimodality. Our algorithm to tackle this problem is based on a coupling of the posterior density for $w$ with an auxiliary random variable $\xi$. The resulting reverse conditional $w|\xi$ of neuron weights given auxiliary random variable is shown to be log concave. In the construction of the posterior distributions we provide some freedom in the choice of the prior. In particular, for Gaussian priors on $w$ with suitably small variance, the resulting marginal density of the auxiliary variable $\xi$ is proven to be strictly log concave for all dimensions $d$. For a uniform prior on the unit $\ell_1$ ball, evidence is given that the density of $\xi$ is again strictly log concave for sufficiently large $d$. The score of the marginal density of the auxiliary random variable $\xi$ is determined by an expectation over $w|\xi$ and thus can be computed by various rapidly mixing Markov Chain Monte Carlo methods. Moreover, the computation of the score of $\xi$ permits methods of sampling $\xi$ by a stochastic diffusion (Langevin dynamics) with drift function built from this score. With such dynamics, information-theoretic methods pioneered by Bakry and Emery show that accurate sampling of $\xi$ is obtained rapidly when its density is indeed strictly log-concave. After which, one more draw from $w|\xi$, produces neuron weights $w$ whose marginal distribution is from the desired posterior.
Toward Fast Reliable Communication at Rates Near Capacity with Gaussian Noise
Jun 19, 2010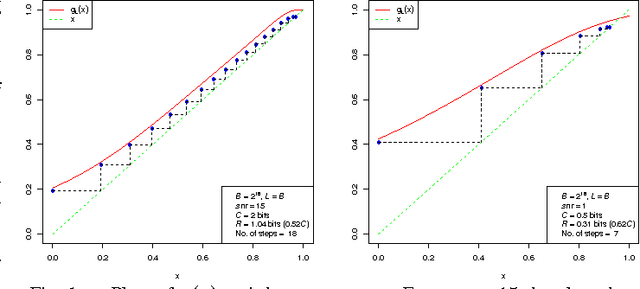
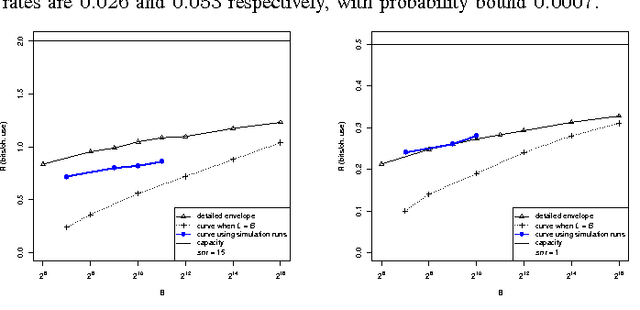
For the additive Gaussian noise channel with average codeword power constraint, sparse superposition codes and adaptive successive decoding is developed. Codewords are linear combinations of subsets of vectors, with the message indexed by the choice of subset. A feasible decoding algorithm is presented. Communication is reliable with error probability exponentially small for all rates below the Shannon capacity.