 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficiency of Convolutional Neural Networks
Apr 04, 2024



Since the breakthrough performance of AlexNet in 2012, convolutional neural networks (convnets) have grown into extremely powerful vision models. Deep learning researchers have used convnets to produce accurate results that were unachievable a decade ago. Yet computer scientists make computational efficiency their primary objective. Accuracy with exorbitant cost is not acceptable; an algorithm must also minimize its computational requirements. Confronted with the daunting computation that convnets use, deep learning researchers also became interested in efficiency. Researchers applied tremendous effort to find the convnet architectures that have the greatest efficiency. However, skepticism grew among researchers and engineers alike about the relevance of arithmetic complexity. Contrary to the prevailing view that latency and arithmetic complexity are irreconcilable, a simple formula relates both through computational efficiency. This insight enabled us to co-optimize the separate factors that determine latency. We observed that the degenerate conv2d layers that produce the best accuracy-complexity trade-off also have low operational intensity. Therefore, kernels that implement these layers use significant memory resources. We solved this optimization problem with block-fusion kernels that implement all layers of a residual block, thereby creating temporal locality, avoiding communication, and reducing workspace size. Our ConvFirst model with block-fusion kernels ran approximately four times as fast as the ConvNeXt baseline with PyTorch Inductor, at equal accuracy on the ImageNet-1K classification task. Our unified approach to convnet efficiency envisions a new era of models and kernels that achieve greater accuracy at lower cost.
Fast Algorithms for Convolutional Neural Networks
Nov 10, 2015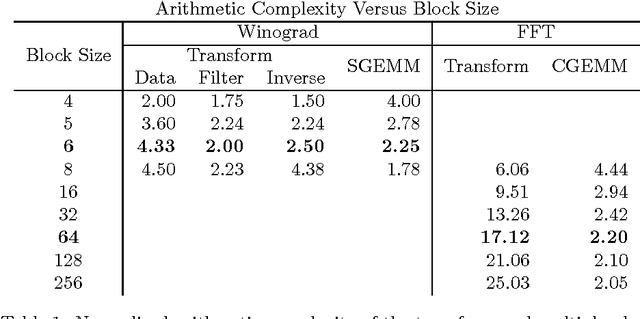
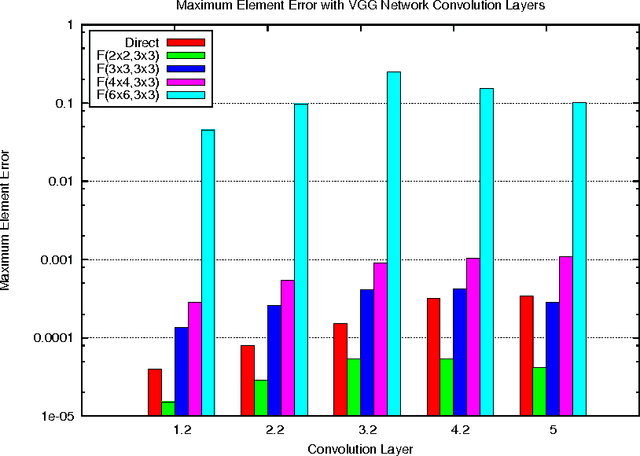
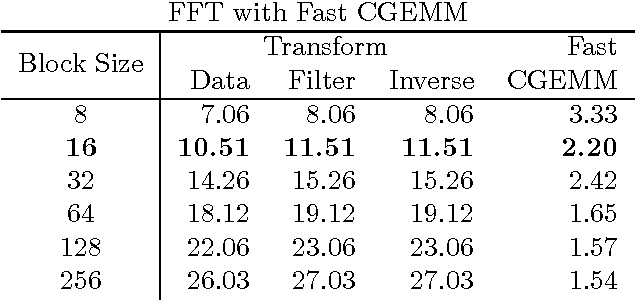
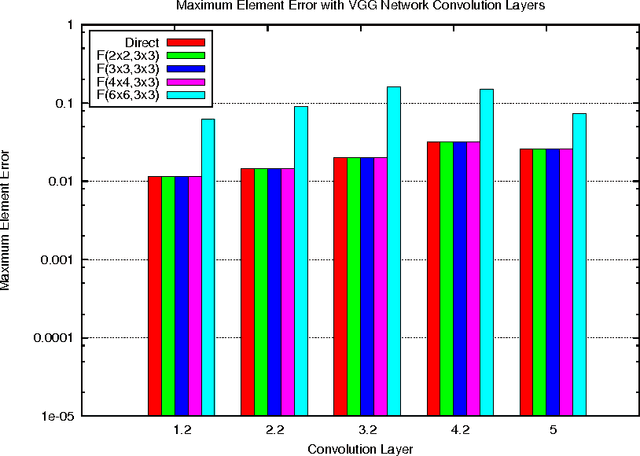
Deep convolutional neural networks take GPU days of compute time to train on large data sets. Pedestrian detection for self driving cars requires very low latency. Image recognition for mobile phones is constrained by limited processing resources. The success of convolutional neural networks in these situations is limited by how fast we can compute them. Conventional FFT based convolution is fast for large filters, but state of the art convolutional neural networks use small, 3x3 filters. We introduce a new class of fast algorithms for convolutional neural networks using Winograd's minimal filtering algorithms. The algorithms compute minimal complexity convolution over small tiles, which makes them fast with small filters and small batch sizes. We benchmark a GPU implementation of our algorithm with the VGG network and show state of the art throughput at batch sizes from 1 to 64.
maxDNN: An Efficient Convolution Kernel for Deep Learning with Maxwell GPUs
Jan 30, 2015
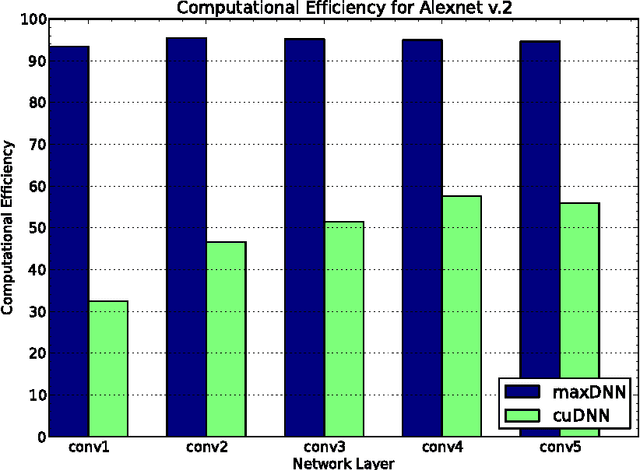

This paper describes maxDNN, a computationally efficient convolution kernel for deep learning with the NVIDIA Maxwell GPU. maxDNN reaches 96.3% computational efficiency on typical deep learning network architectures. The design combines ideas from cuda-convnet2 with the Maxas SGEMM assembly code. We only address forward propagation (FPROP) operation of the network, but we believe that the same techniques used here will be effective for backward propagation (BPROP) as well.