Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemaxDNN: An Efficient Convolution Kernel for Deep Learning with Maxwell GPUs
Paper and Code

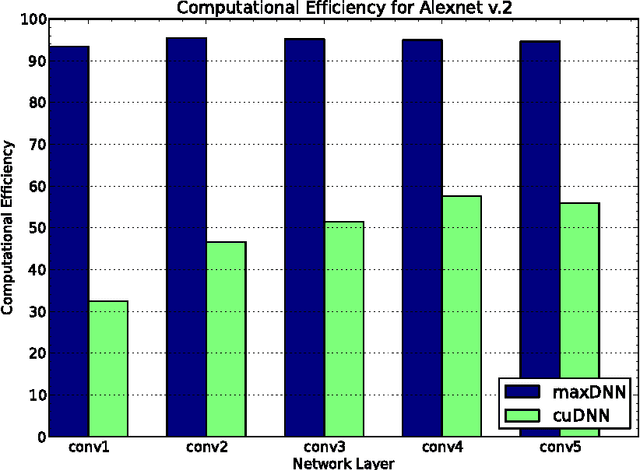

This paper describes maxDNN, a computationally efficient convolution kernel for deep learning with the NVIDIA Maxwell GPU. maxDNN reaches 96.3% computational efficiency on typical deep learning network architectures. The design combines ideas from cuda-convnet2 with the Maxas SGEMM assembly code. We only address forward propagation (FPROP) operation of the network, but we believe that the same techniques used here will be effective for backward propagation (BPROP) as well.
* 7 pages, 2 figures, 1 table
View paper on