 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLitSumm: Large language models for literature summarisation of non-coding RNAs
Nov 06, 2023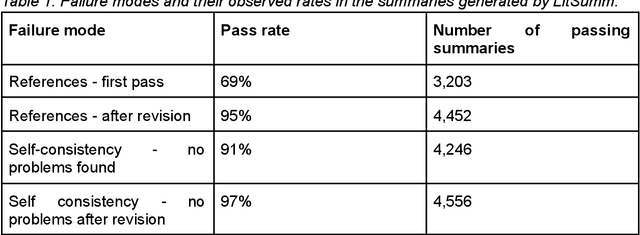
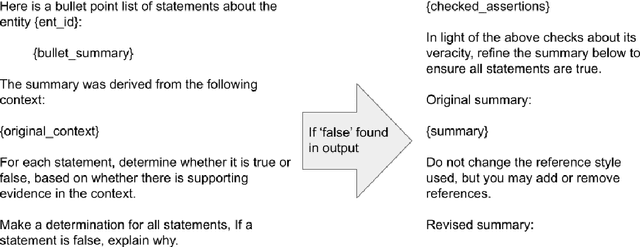

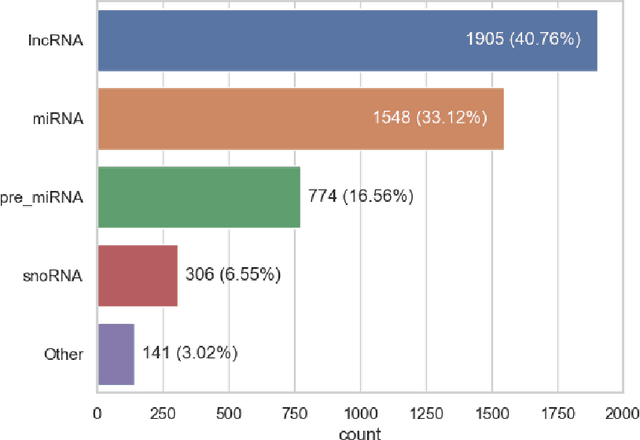
Motivation: Curation of literature in life sciences is a growing challenge. The continued increase in the rate of publication, coupled with the relatively fixed number of curators worldwide presents a major challenge to developers of biomedical knowledgebases. Very few knowledgebases have resources to scale to the whole relevant literature and all have to prioritise their efforts. Results: In this work, we take a first step to alleviating the lack of curator time in RNA science by generating summaries of literature for non-coding RNAs using large language models (LLMs). We demonstrate that high-quality, factually accurate summaries with accurate references can be automatically generated from the literature using a commercial LLM and a chain of prompts and checks. Manual assessment was carried out for a subset of summaries, with the majority being rated extremely high quality. We also applied the most commonly used automated evaluation approaches, finding that they do not correlate with human assessment. Finally, we apply our tool to a selection of over 4,600 ncRNAs and make the generated summaries available via the RNAcentral resource. We conclude that automated literature summarization is feasible with the current generation of LLMs, provided careful prompting and automated checking are applied. Availability: Code used to produce these summaries can be found here: https://github.com/RNAcentral/litscan-summarization and the dataset of contexts and summaries can be found here: https://huggingface.co/datasets/RNAcentral/litsumm-v1. Summaries are also displayed on the RNA report pages in RNAcentral (https://rnacentral.org/)
Deeply Learning Derivatives
Oct 17, 2018

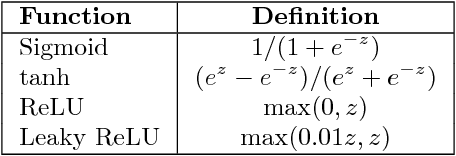

This paper uses deep learning to value derivatives. The approach is broadly applicable, and we use a call option on a basket of stocks as an example. We show that the deep learning model is accurate and very fast, capable of producing valuations a million times faster than traditional models. We develop a methodology to randomly generate appropriate training data and explore the impact of several parameters including layer width and depth, training data quality and quantity on model speed and accuracy.