 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADD: Multi-Agent Drug Discovery Orchestra
Nov 11, 2025Hit identification is a central challenge in early drug discovery, traditionally requiring substantial experimental resources. Recent advances in artificial intelligence, particularly large language models (LLMs), have enabled virtual screening methods that reduce costs and improve efficiency. However, the growing complexity of these tools has limited their accessibility to wet-lab researchers. Multi-agent systems offer a promising solution by combining the interpretability of LLMs with the precision of specialized models and tools. In this work, we present MADD, a multi-agent system that builds and executes customized hit identification pipelines from natural language queries. MADD employs four coordinated agents to handle key subtasks in de novo compound generation and screening. We evaluate MADD across seven drug discovery cases and demonstrate its superior performance compared to existing LLM-based solutions. Using MADD, we pioneer the application of AI-first drug design to five biological targets and release the identified hit molecules. Finally, we introduce a new benchmark of query-molecule pairs and docking scores for over three million compounds to contribute to the agentic future of drug design.
Benchmarking Agentic Systems in Automated Scientific Information Extraction with ChemX
Oct 01, 2025



The emergence of agent-based systems represents a significant advancement in artificial intelligence, with growing applications in automated data extraction. However, chemical information extraction remains a formidable challenge due to the inherent heterogeneity of chemical data. Current agent-based approaches, both general-purpose and domain-specific, exhibit limited performance in this domain. To address this gap, we present ChemX, a comprehensive collection of 10 manually curated and domain-expert-validated datasets focusing on nanomaterials and small molecules. These datasets are designed to rigorously evaluate and enhance automated extraction methodologies in chemistry. To demonstrate their utility, we conduct an extensive benchmarking study comparing existing state-of-the-art agentic systems such as ChatGPT Agent and chemical-specific data extraction agents. Additionally, we introduce our own single-agent approach that enables precise control over document preprocessing prior to extraction. We further evaluate the performance of modern baselines, such as GPT-5 and GPT-5 Thinking, to compare their capabilities with agentic approaches. Our empirical findings reveal persistent challenges in chemical information extraction, particularly in processing domain-specific terminology, complex tabular and schematic representations, and context-dependent ambiguities. The ChemX benchmark serves as a critical resource for advancing automated information extraction in chemistry, challenging the generalization capabilities of existing methods, and providing valuable insights into effective evaluation strategies.
Pharmacophore-Guided Generative Design of Novel Drug-Like Molecules
Oct 01, 2025The integration of artificial intelligence (AI) in early-stage drug discovery offers unprecedented opportunities for exploring chemical space and accelerating hit-to-lead optimization. However, docking optimization in generative approaches is computationally expensive and may lead to inaccurate results. Here, we present a novel generative framework that balances pharmacophore similarity to reference compounds with structural diversity from active molecules. The framework allows users to provide custom reference sets, including FDA-approved drugs or clinical candidates, and guides the \textit{de novo} generation of potential therapeutics. We demonstrate its applicability through a case study targeting estrogen receptor modulators and antagonists for breast cancer. The generated compounds maintain high pharmacophoric fidelity to known active molecules while introducing substantial structural novelty, suggesting strong potential for functional innovation and patentability. Comprehensive evaluation of the generated molecules against common drug-like properties confirms the robustness and pharmaceutical relevance of the approach.
Hybrid Generative AI for De Novo Design of Co-Crystals with Enhanced Tabletability
Oct 22, 2024



Co-crystallization is an accessible way to control physicochemical characteristics of organic crystals, which finds many biomedical applications. In this work, we present Generative Method for Co-crystal Design (GEMCODE), a novel pipeline for automated co-crystal screening based on the hybridization of deep generative models and evolutionary optimization for broader exploration of the target chemical space. GEMCODE enables fast de novo co-crystal design with target tabletability profiles, which is crucial for the development of pharmaceuticals. With a series of experimental studies highlighting validation and discovery cases, we show that GEMCODE is effective even under realistic computational constraints. Furthermore, we explore the potential of language models in generating co-crystals. Finally, we present numerous previously unknown co-crystals predicted by GEMCODE and discuss its potential in accelerating drug development.
Unveiling the Potential of AI for Nanomaterial Morphology Prediction
May 31, 2024Creation of nanomaterials with specific morphology remains a complex experimental process, even though there is a growing demand for these materials in various industry sectors. This study explores the potential of AI to predict the morphology of nanoparticles within the data availability constraints. For that, we first generated a new multi-modal dataset that is double the size of analogous studies. Then, we systematically evaluated performance of classical machine learning and large language models in prediction of nanomaterial shapes and sizes. Finally, we prototyped a text-to-image system, discussed the obtained empirical results, as well as the limitations and promises of existing approaches.
Self-supervised learning for analysis of temporal and morphological drug effects in cancer cell imaging data
Mar 07, 2022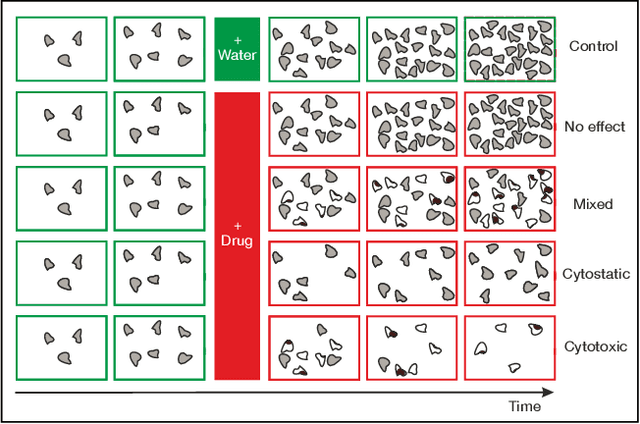

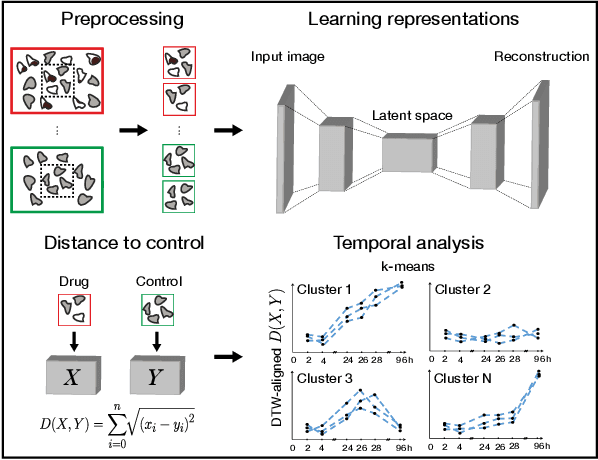
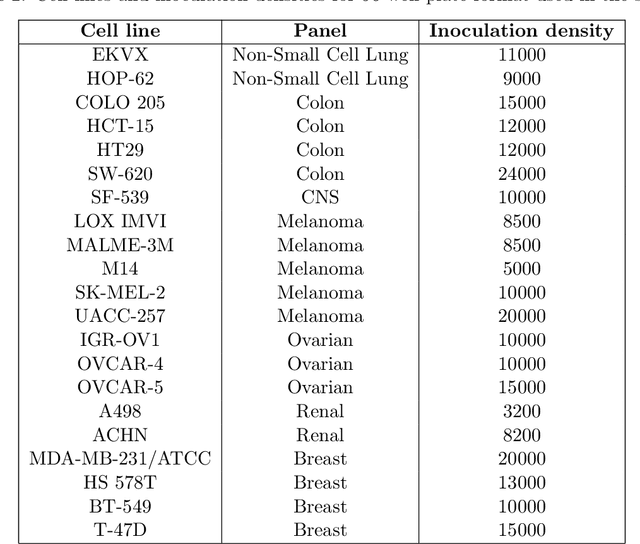
In this work, we propose two novel methodologies to study temporal and morphological phenotypic effects caused by different experimental conditions using imaging data. As a proof of concept, we apply them to analyze drug effects in 2D cancer cell cultures. We train a convolutional autoencoder on 1M images dataset with random augmentations and multi-crops to use as feature extractor. We systematically compare it to the pretrained state-of-the-art models. We further use the feature extractor in two ways. First, we apply distance-based analysis and dynamic time warping to cluster temporal patterns of 31 drugs. We identify clusters allowing annotation of drugs as having cytotoxic, cytostatic, mixed or no effect. Second, we implement an adversarial/regularized learning setup to improve classification of 31 drugs and visualize image regions that contribute to the improvement. We increase top-3 classification accuracy by 8% on average and mine examples of morphological feature importance maps. We provide the feature extractor and the weights to foster transfer learning applications in biology. We also discuss utility of other pretrained models and applicability of our methods to other types of biomedical data.
Comparing representations of biological data learned with different AI paradigms, augmenting and cropping strategies
Mar 07, 2022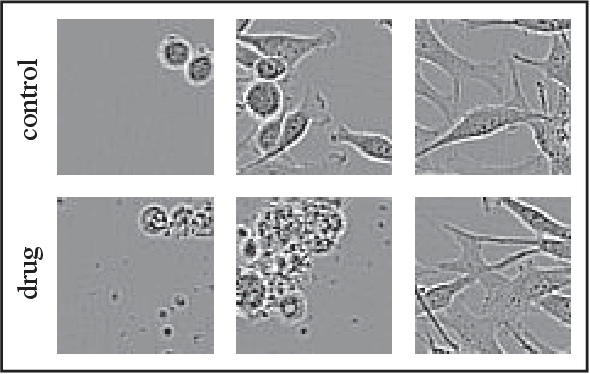
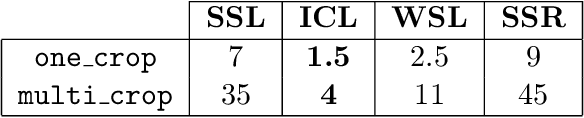

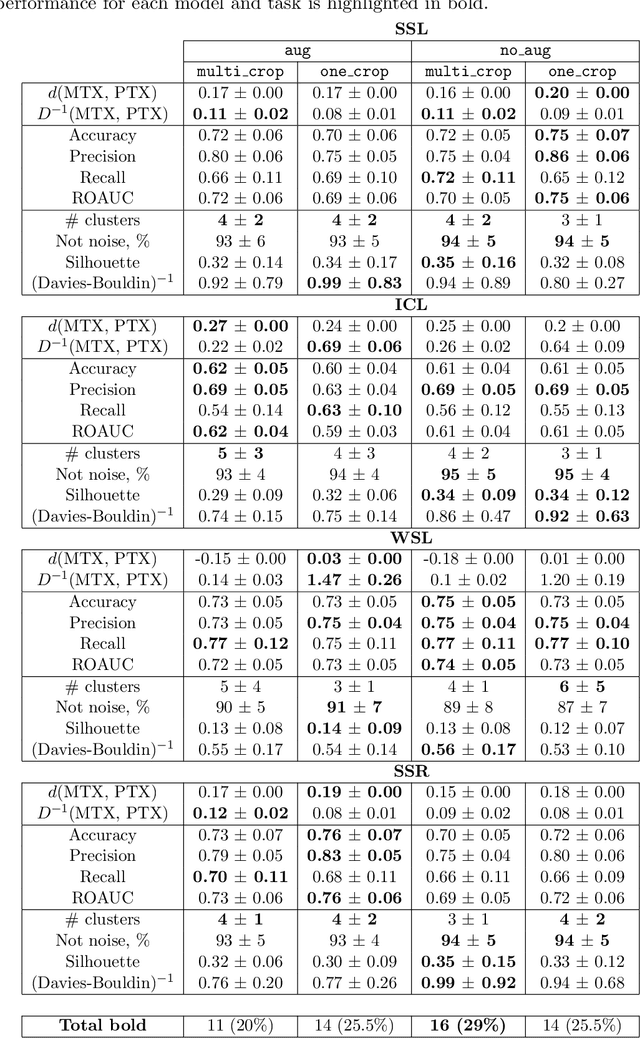
Recent advances in computer vision and robotics enabled automated large-scale biological image analysis. Various machine learning approaches have been successfully applied to phenotypic profiling. However, it remains unclear how they compare in terms of biological feature extraction. In this study, we propose a simple CNN architecture and implement 4 different representation learning approaches. We train 16 deep learning setups on the 770k cancer cell images dataset under identical conditions, using different augmenting and cropping strategies. We compare the learned representations by evaluating multiple metrics for each of three downstream tasks: i) distance-based similarity analysis of known drugs, ii) classification of drugs versus controls, iii) clustering within cell lines. We also compare training times and memory usage. Among all tested setups, multi-crops and random augmentations generally improved performance across tasks, as expected. Strikingly, self-supervised (implicit contrastive learning) models showed competitive performance being up to 11 times faster to train. Self-supervised regularized learning required the most of memory and computation to deliver arguably the most informative features. We observe that no single combination of augmenting and cropping strategies consistently results in top performance across tasks and recommend prospective research directions.