 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Datasets with Demographics through Large Language Models: What's in a Name?
Sep 17, 2024Enriching datasets with demographic information, such as gender, race, and age from names, is a critical task in fields like healthcare, public policy, and social sciences. Such demographic insights allow for more precise and effective engagement with target populations. Despite previous efforts employing hidden Markov models and recurrent neural networks to predict demographics from names, significant limitations persist: the lack of large-scale, well-curated, unbiased, publicly available datasets, and the lack of an approach robust across datasets. This scarcity has hindered the development of traditional supervised learning approaches. In this paper, we demonstrate that the zero-shot capabilities of Large Language Models (LLMs) can perform as well as, if not better than, bespoke models trained on specialized data. We apply these LLMs to a variety of datasets, including a real-life, unlabelled dataset of licensed financial professionals in Hong Kong, and critically assess the inherent demographic biases in these models. Our work not only advances the state-of-the-art in demographic enrichment but also opens avenues for future research in mitigating biases in LLMs.
Deep learning pipeline for image classification on mobile phones
May 31, 2022
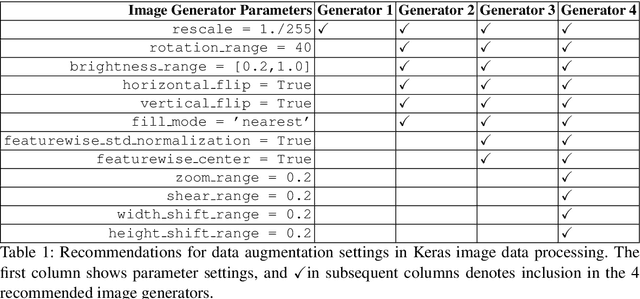
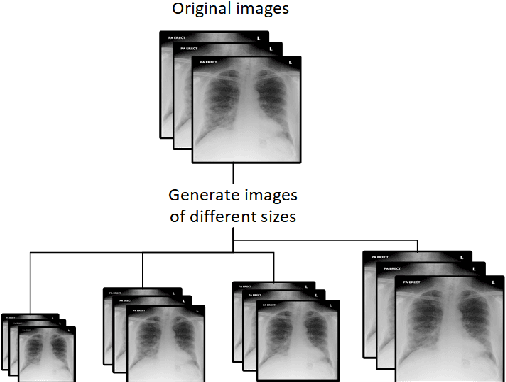

This article proposes and documents a machine-learning framework and tutorial for classifying images using mobile phones. Compared to computers, the performance of deep learning model performance degrades when deployed on a mobile phone and requires a systematic approach to find a model that performs optimally on both computers and mobile phones. By following the proposed pipeline, which consists of various computational tools, simple procedural recipes, and technical considerations, one can bring the power of deep learning medical image classification to mobile devices, potentially unlocking new domains of applications. The pipeline is demonstrated on four different publicly available datasets: COVID X-rays, COVID CT scans, leaves, and colorectal cancer. We used two application development frameworks: TensorFlow Lite (real-time testing) and Flutter (digital image testing) to test the proposed pipeline. We found that transferring deep learning models to a mobile phone is limited by hardware and classification accuracy drops. To address this issue, we proposed this pipeline to find an optimized model for mobile phones. Finally, we discuss additional applications and computational concerns related to deploying deep-learning models on phones, including real-time analysis and image preprocessing. We believe the associated documentation and code can help physicians and medical experts develop medical image classification applications for distribution.
* 20 pages