 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-powered fossil shark tooth identification: Unleashing the potential of Convolutional Neural Networks
May 07, 2024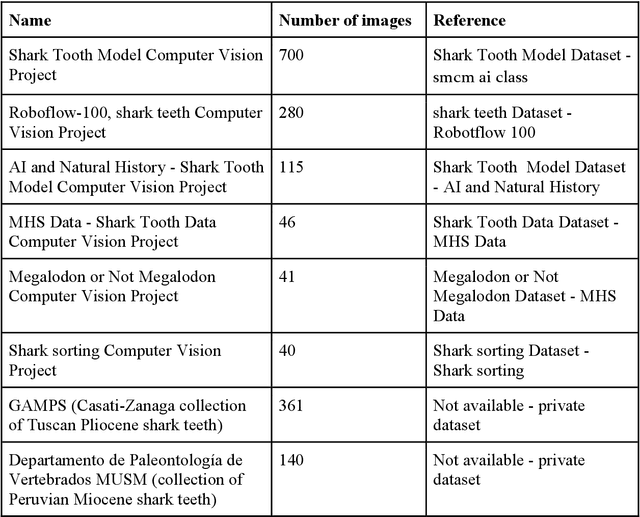

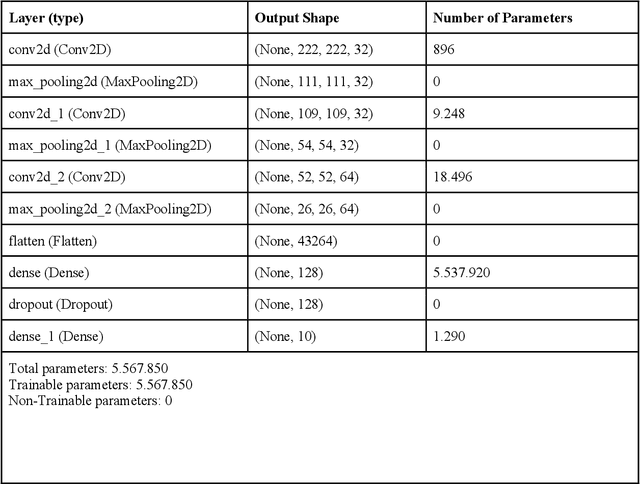
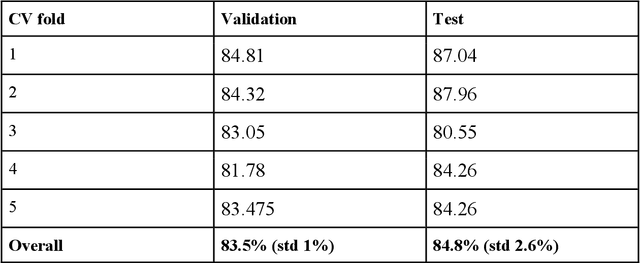
All fields of knowledge are being impacted by Artificial Intelligence. In particular, the Deep Learning paradigm enables the development of data analysis tools that support subject matter experts in a variety of sectors, from physics up to the recognition of ancient languages. Palaeontology is now observing this trend as well. This study explores the capability of Convolutional Neural Networks (CNNs), a particular class of Deep Learning algorithms specifically crafted for computer vision tasks, to classify images of isolated fossil shark teeth gathered from online datasets as well as from the authors$'$ experience on Peruvian Miocene and Italian Pliocene fossil assemblages. The shark taxa that are included in the final, composite dataset (which consists of more than one thousand images) are representative of both extinct and extant genera, namely, Carcharhinus, Carcharias, Carcharocles, Chlamydoselachus, Cosmopolitodus, Galeocerdo, Hemipristis, Notorynchus, Prionace and Squatina. We developed a CNN, named SharkNet-X, specifically tailored on our recognition task, reaching a 5-fold cross validated mean accuracy of 0.85 to identify images containing a single shark tooth. Furthermore, we elaborated a visualization of the features extracted from images using the last dense layer of the CNN, achieved through the application of the clustering technique t-SNE. In addition, in order to understand and explain the behaviour of the CNN while giving a paleontological point of view on the results, we introduced the explainability method SHAP. To the best of our knowledge, this is the first instance in which this method is applied to the field of palaeontology. The main goal of this work is to showcase how Deep Learning techniques can aid in identifying isolated fossil shark teeth, paving the way for developing new information tools for automating the recognition and classification of fossils.
Asteroids co-orbital motion classification based on Machine Learning
Sep 19, 2023



In this work, we explore how to classify asteroids in co-orbital motion with a given planet using Machine Learning. We consider four different kinds of motion in mean motion resonance with the planet, nominally Tadpole, Horseshoe and Quasi-satellite, building 3 datasets defined as Real (taking the ephemerides of real asteroids from the JPL Horizons system), Ideal and Perturbed (both simulated, obtained by propagating initial conditions considering two different dynamical systems) for training and testing the Machine Learning algorithms in different conditions. The time series of the variable theta (angle related to the resonance) are studied with a data analysis pipeline defined ad hoc for the problem and composed by: data creation and annotation, time series features extraction thanks to the tsfresh package (potentially followed by selection and standardization) and the application of Machine Learning algorithms for Dimensionality Reduction and Classification. Such approach, based on features extracted from the time series, allows to work with a smaller number of data with respect to Deep Learning algorithms, also allowing to define a ranking of the importance of the features. Physical Interpretability of the features is another key point of this approach. In addition, we introduce the SHapley Additive exPlanations for Explainability technique. Different training and test sets are used, in order to understand the power and the limits of our approach. The results show how the algorithms are able to identify and classify correctly the time series, with a high degree of performance.
Efficacy of MRI data harmonization in the age of machine learning. A multicenter study across 36 datasets
Nov 08, 2022Pooling publicly-available MRI data from multiple sites allows to assemble extensive groups of subjects, increase statistical power, and promote data reuse with machine learning techniques. The harmonization of multicenter data is necessary to reduce the confounding effect associated with non-biological sources of variability in the data. However, when applied to the entire dataset before machine learning, the harmonization leads to data leakage, because information outside the training set may affect model building, and potentially falsely overestimate performance. We propose a 1) measurement of the efficacy of data harmonization; 2) harmonizer transformer, i.e., an implementation of the ComBat harmonization allowing its encapsulation among the preprocessing steps of a machine learning pipeline, avoiding data leakage. We tested these tools using brain T1-weighted MRI data from 1740 healthy subjects acquired at 36 sites. After harmonization, the site effect was removed or reduced, and we measured the data leakage effect in predicting individual age from MRI data, highlighting that introducing the harmonizer transformer into a machine learning pipeline allows for avoiding data leakage.