 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Context-Rich Automated Biodiversity Assessments: Deriving AI-Powered Insights from Camera Trap Data
Nov 21, 2024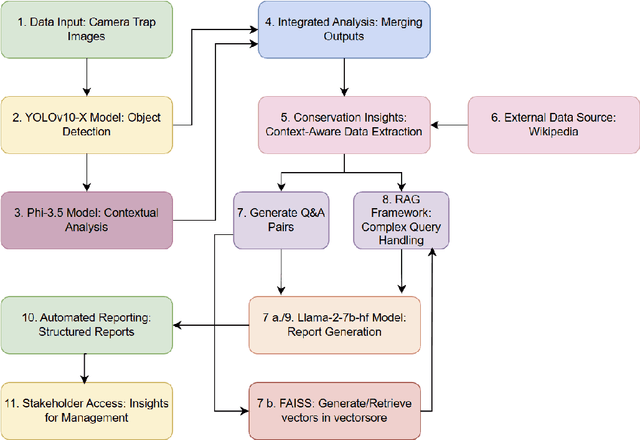
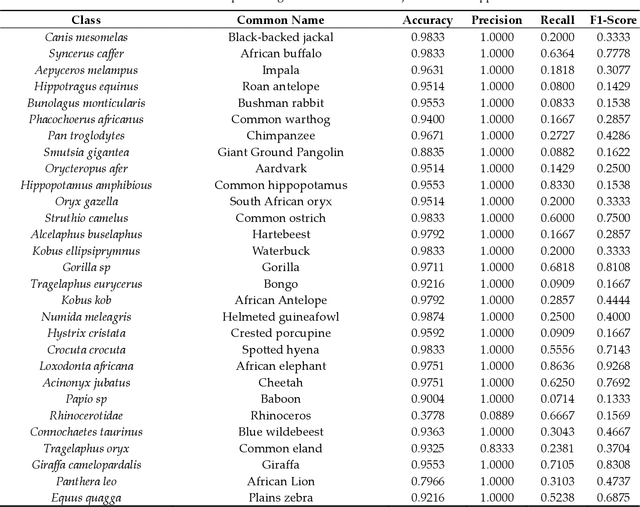
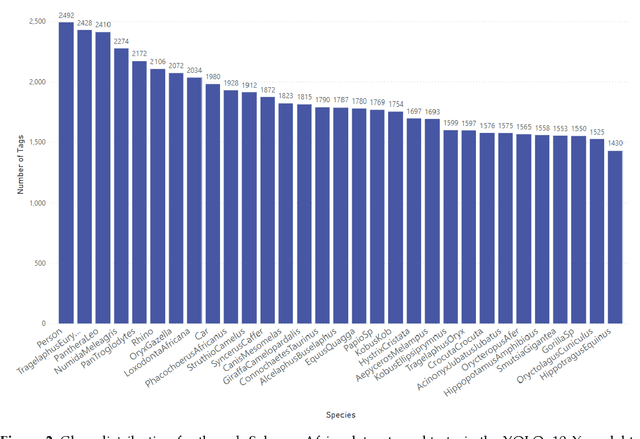
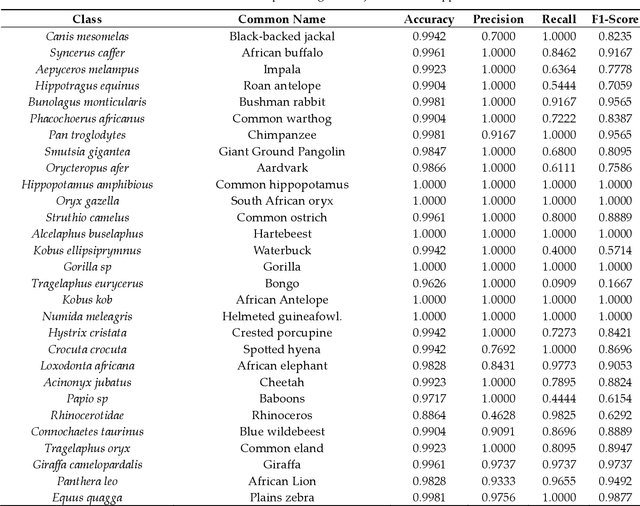
Camera traps offer enormous new opportunities in ecological studies, but current automated image analysis methods often lack the contextual richness needed to support impactful conservation outcomes. Here we present an integrated approach that combines deep learning-based vision and language models to improve ecological reporting using data from camera traps. We introduce a two-stage system: YOLOv10-X to localise and classify species (mammals and birds) within images, and a Phi-3.5-vision-instruct model to read YOLOv10-X binding box labels to identify species, overcoming its limitation with hard to classify objects in images. Additionally, Phi-3.5 detects broader variables, such as vegetation type, and time of day, providing rich ecological and environmental context to YOLO's species detection output. When combined, this output is processed by the model's natural language system to answer complex queries, and retrieval-augmented generation (RAG) is employed to enrich responses with external information, like species weight and IUCN status (information that cannot be obtained through direct visual analysis). This information is used to automatically generate structured reports, providing biodiversity stakeholders with deeper insights into, for example, species abundance, distribution, animal behaviour, and habitat selection. Our approach delivers contextually rich narratives that aid in wildlife management decisions. By providing contextually rich insights, our approach not only reduces manual effort but also supports timely decision-making in conservation, potentially shifting efforts from reactive to proactive management.