 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Perinuclear Ring-based Image Segmentation Method for Acute Lymphoblastic Leukemia Classification
May 13, 2026Automated analysis of peripheral blood smears for Acute Lymphoblastic Leukemia (ALL) is hindered by low contrast and substantial variability in cytoplasmic appearance, which complicate conventional membrane-based segmentation. We found that many recent approaches rely on heavy neural architectures and extensive training, but still struggle to generalize across staining and acquisition variability. To address these limitations, we propose the Perinuclear Ring-based Image Segmentation Method (PRISM), which replaces explicit cytoplasmic delineation with adaptive concentric zones constructed around the nucleus. These perinuclear regions enable the extraction of robust cytoplasmic descriptors by integrating color information with texture statistics derived from grey-level co-occurrence patterns, without requiring accurate cell-boundary detection. A calibrated stacking ensemble of traditional classifiers leverages these descriptors to achieve a high performance, with an accuracy of 98.46% and a precision-recall AUC of 0.9937.
Exploiting Test-Time Augmentation in Federated Learning for Brain Tumor MRI Classification
Jan 19, 2026Efficient brain tumor diagnosis is crucial for early treatment; however, it is challenging because of lesion variability and image complexity. We evaluated convolutional neural networks (CNNs) in a federated learning (FL) setting, comparing models trained on original versus preprocessed MRI images (resizing, grayscale conversion, normalization, filtering, and histogram equalization). Preprocessing alone yielded negligible gains; combined with test-time augmentation (TTA), it delivered consistent, statistically significant improvements in federated MRI classification (p<0.001). In practice, TTA should be the default inference strategy in FL-based medical imaging; when the computational budget permits, pairing TTA with light preprocessing provides additional reliable gains.
Generalizable Hyperparameter Optimization for Federated Learning on Non-IID Cancer Images
Jan 19, 2026Deep learning for cancer histopathology training conflicts with privacy constraints in clinical settings. Federated Learning (FL) mitigates this by keeping data local; however, its performance depends on hyperparameter choices under non-independent and identically distributed (non-IID) client datasets. This paper examined whether hyperparameters optimized on one cancer imaging dataset generalized across non-IID federated scenarios. We considered binary histopathology tasks for ovarian and colorectal cancers. We perform centralized Bayesian hyperparameter optimization and transfer dataset-specific optima to the non-IID FL setup. The main contribution of this study is the introduction of a simple cross-dataset aggregation heuristic by combining configurations by averaging the learning rates and considering the modal optimizers and batch sizes. This combined configuration achieves a competitive classification performance.
Productivity profile of CNPq scholarship researchers in computer science from 2017 to 2021
Jul 19, 2024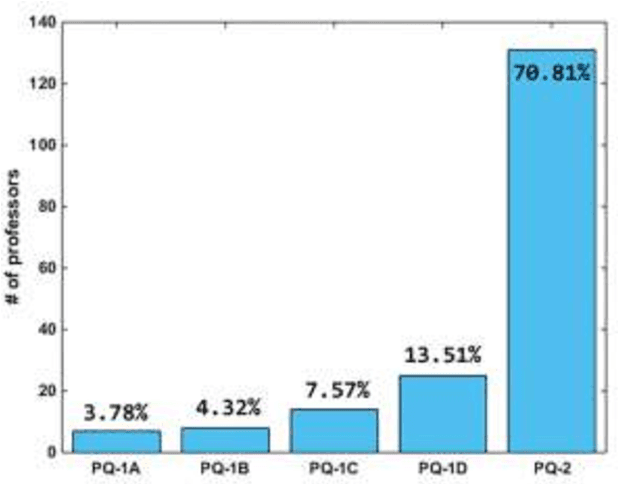

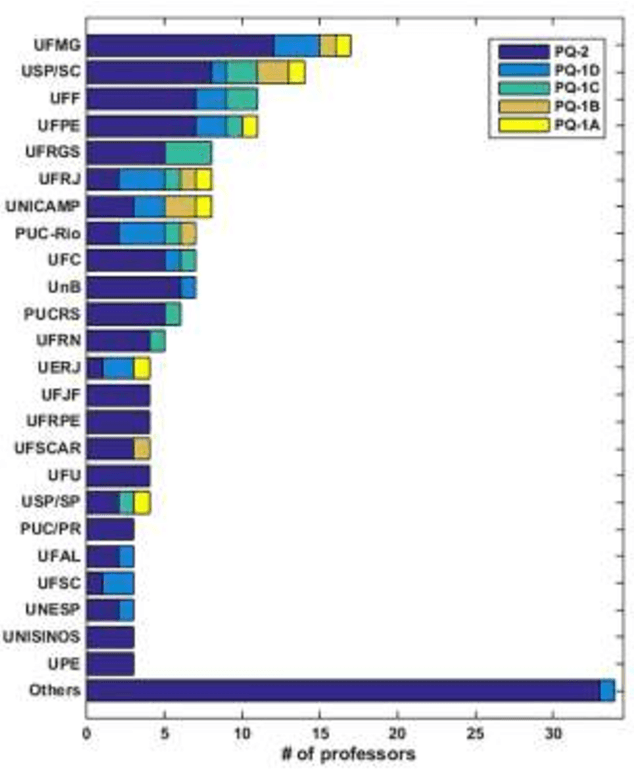

Productivity in Research (PQ) is a scholarship granted by CNPq (Brazilian National Council for Scientific and Technological Development). This scholarship aims to recognize a few selected faculty researchers for their scientific production, outstanding technology and innovation in their respective areas of knowledge. In the present study, we evaluated the scientific production of the 185 researchers in the Computer Science area granted with PQ scholarship in the last PQ selection notice. To evaluate the productivity of each professor, we considered papers published in scientific journals and conferences (complete works) in a five years period (from 2017 to 2021). We analyzed the productivity in terms of both quantity and quality. We also evaluated its distribution over the country, universities and research facilities, as well as, the co-authorship network produced.
Contour polygonal approximation using shortest path in networks
Nov 18, 2013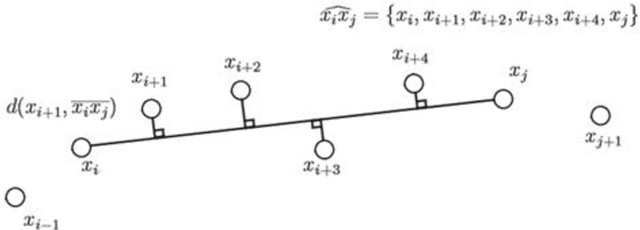
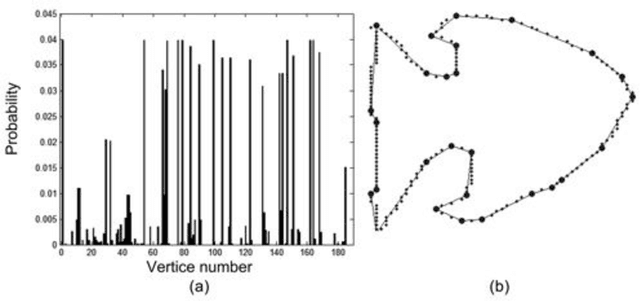
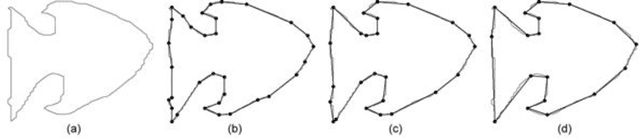
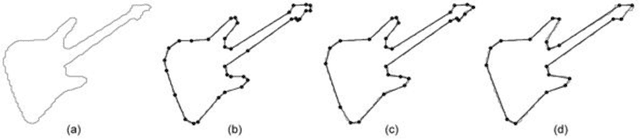
Contour polygonal approximation is a simplified representation of a contour by line segments, so that the main characteristics of the contour remain in a small number of line segments. This paper presents a novel method for polygonal approximation based on the Complex Networks theory. We convert each point of the contour into a vertex, so that we model a regular network. Then we transform this network into a Small-World Complex Network by applying some transformations over its edges. By analyzing of network properties, especially the geodesic path, we compute the polygonal approximation. The paper presents the main characteristics of the method, as well as its functionality. We evaluate the proposed method using benchmark contours, and compare its results with other polygonal approximation methods.
Fractal and Multi-Scale Fractal Dimension analysis: a comparative study of Bouligand-Minkowski method
Jan 16, 2012


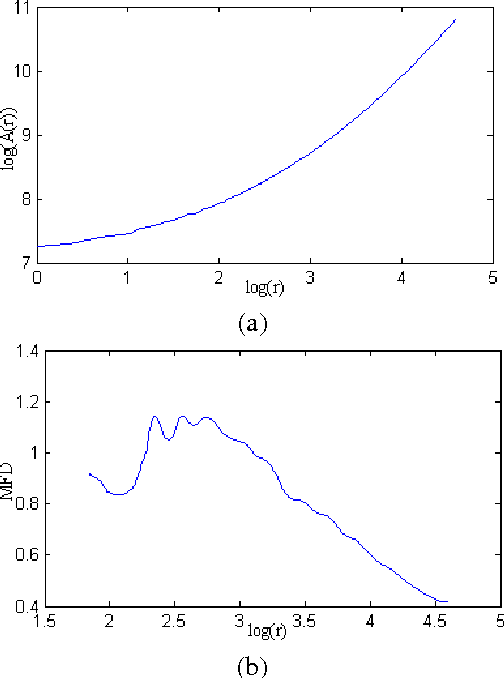
Shape is one of the most important visual attributes to characterize objects, playing a important role in pattern recognition. There are various approaches to extract relevant information of a shape. An approach widely used in shape analysis is the complexity, and Fractal Dimension and Multi-Scale Fractal Dimension are both well-known methodologies to estimate it. This papers presents a comparative study between Fractal Dimension and Multi-Scale Fractal Dimension in a shape analysis context. Through experimental comparison using a shape database previously classified, both methods are compared. Different parameters configuration of each method are considered and a discussion about the results of each method is also presented.