Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA system for information extraction from scientific texts in Russian
Sep 14, 2021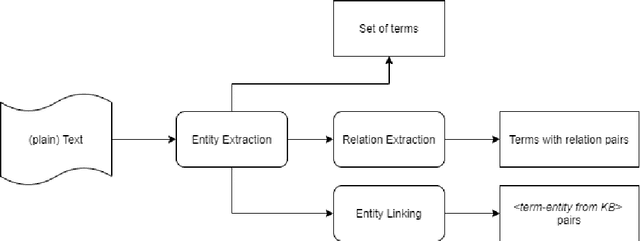
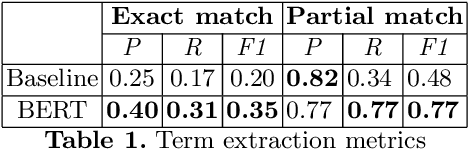
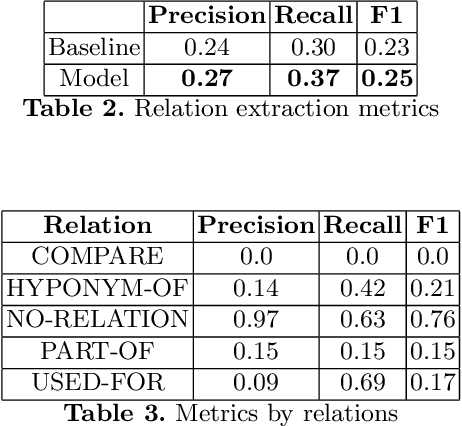

In this paper, we present a system for information extraction from scientific texts in the Russian language. The system performs several tasks in an end-to-end manner: term recognition, extraction of relations between terms, and term linking with entities from the knowledge base. These tasks are extremely important for information retrieval, recommendation systems, and classification. The advantage of the implemented methods is that the system does not require a large amount of labeled data, which saves time and effort for data labeling and therefore can be applied in low- and mid-resource settings. The source code is publicly available and can be used for different research purposes.
Via