 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification and Clustering of Sentence-Level Embeddings of Scientific Articles Generated by Contrastive Learning
Mar 30, 2024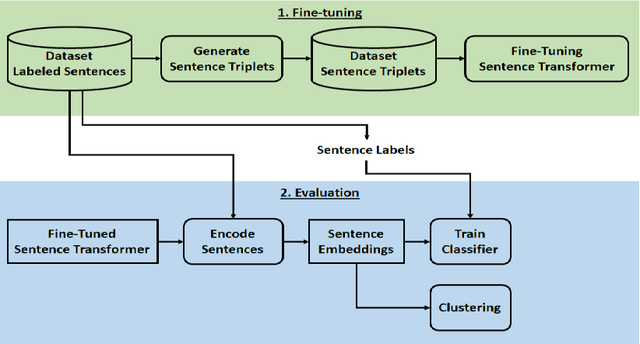


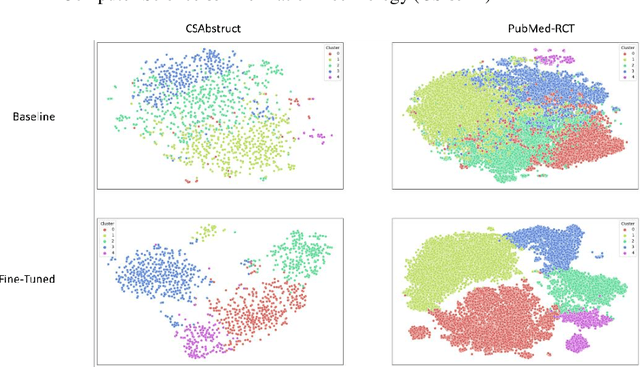
Scientific articles are long text documents organized into sections, each describing aspects of the research. Analyzing scientific production has become progressively challenging due to the increase in the number of available articles. Within this scenario, our approach consisted of fine-tuning transformer language models to generate sentence-level embeddings from scientific articles, considering the following labels: background, objective, methods, results, and conclusion. We trained our models on three datasets with contrastive learning. Two datasets are from the article's abstracts in the computer science and medical domains. Also, we introduce PMC-Sents-FULL, a novel dataset of sentences extracted from the full texts of medical articles. We compare the fine-tuned and baseline models in clustering and classification tasks to evaluate our approach. On average, clustering agreement measures values were five times higher. For the classification measures, in the best-case scenario, we had an average improvement in F1-micro of 30.73\%. Results show that fine-tuning sentence transformers with contrastive learning and using the generated embeddings in downstream tasks is a feasible approach to sentence classification in scientific articles. Our experiment codes are available on GitHub.
Evaluating Named Entity Recognition: Comparative Analysis of Mono- and Multilingual Transformer Models on Brazilian Corporate Earnings Call Transcriptions
Mar 18, 2024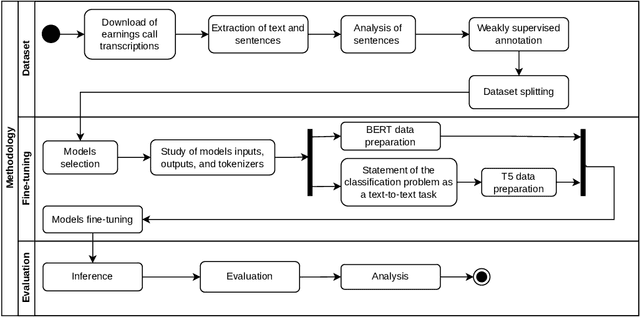

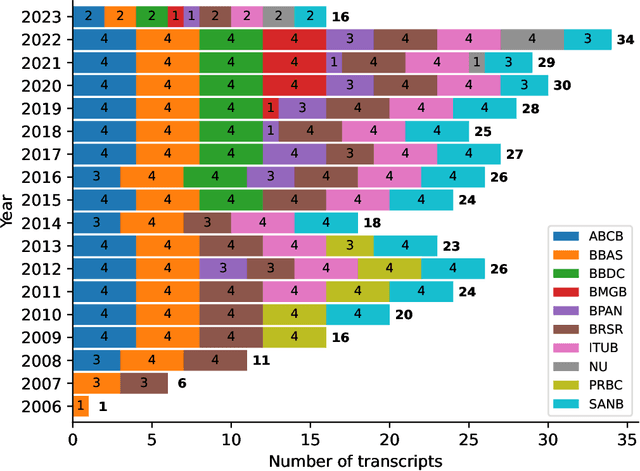

Named Entity Recognition (NER) is a Natural Language Processing technique for extracting information from textual documents. However, much of the existing research on NER has been centered around English-language documents, leaving a gap in the availability of datasets tailored to the financial domain in Portuguese. This study addresses the need for NER within the financial domain, focusing on Portuguese-language texts extracted from earnings call transcriptions of Brazilian banks. By curating a comprehensive dataset comprising 384 transcriptions and leveraging weak supervision techniques for annotation, we evaluate the performance of monolingual models trained on Portuguese (BERTimbau and PTT5) and multilingual models (mBERT and mT5). Notably, we introduce a novel approach that reframes the token classification task as a text generation problem, enabling fine-tuning and evaluation of T5 models. Following the fine-tuning of the models, we conduct an evaluation on the test dataset, employing performance and error metrics. Our findings reveal that BERT-based models consistently outperform T5-based models. Furthermore, while the multilingual models exhibit comparable macro F1-scores, BERTimbau demonstrates superior performance over PTT5. A manual analysis of sentences generated by PTT5 and mT5 unveils a degree of similarity ranging from 0.89 to 1.0, between the original and generated sentences. However, critical errors emerge as both models exhibit discrepancies, such as alterations to monetary and percentage values, underscoring the importance of accuracy and consistency in the financial domain. Despite these challenges, PTT5 and mT5 achieve impressive macro F1-scores of 98.52% and 98.85%, respectively, with our proposed approach. Furthermore, our study sheds light on notable disparities in memory and time consumption for inference across the models.