 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Catastrophic Interference with Biased Competition
Jul 03, 2020

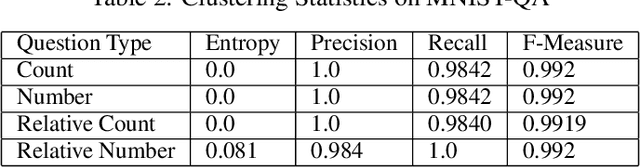

We present here a model to take advantage of the multi-task nature of complex datasets by learning to separate tasks and subtasks in and end to end manner by biasing competitive interactions in the network. This method does not require additional labelling or reformatting of data in a dataset. We propose an alternate view to the monolithic one-task-fits-all learning of multi-task problems, and describe a model based on a theory of neuronal attention from neuroscience, proposed by Desimone. We create and exhibit a new toy dataset, based on the MNIST dataset, which we call MNIST-QA, for testing Visual Question Answering architectures in a low-dimensional environment while preserving the more difficult components of the Visual Question Answering task, and demonstrate the proposed network architecture on this new dataset, as well as on COCO-QA and DAQUAR-FULL. We then demonstrate that this model eliminates catastrophic interference between tasks on a newly created toy dataset and provides competitive results in the Visual Question Answering space. We provide further evidence that Visual Question Answering can be approached as a multi-task problem, and demonstrate that this new architecture based on the Biased Competition model is capable of learning to separate and learn the tasks in an end-to-end fashion without the need for task labels.
Visual Question Answering as a Multi-Task Problem
Jul 03, 2020



Visual Question Answering(VQA) is a highly complex problem set, relying on many sub-problems to produce reasonable answers. In this paper, we present the hypothesis that Visual Question Answering should be viewed as a multi-task problem, and provide evidence to support this hypothesis. We demonstrate this by reformatting two commonly used Visual Question Answering datasets, COCO-QA and DAQUAR, into a multi-task format and train these reformatted datasets on two baseline networks, with one designed specifically to eliminate other possible causes for performance changes as a result of the reformatting. Though the networks demonstrated in this paper do not achieve strongly competitive results, we find that the multi-task approach to Visual Question Answering results in increases in performance of 5-9% against the single-task formatting, and that the networks reach convergence much faster than in the single-task case. Finally we discuss possible reasons for the observed difference in performance, and perform additional experiments which rule out causes not associated with the learning of the dataset as a multi-task problem.