Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Tail Weight of a Distribution Via Hazard Rate
Oct 06, 2020
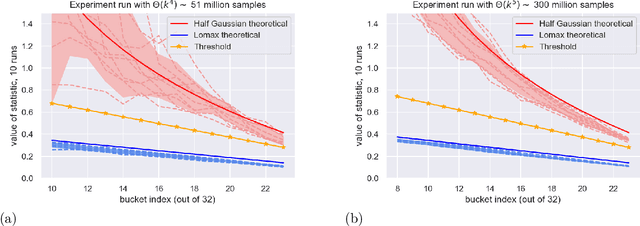
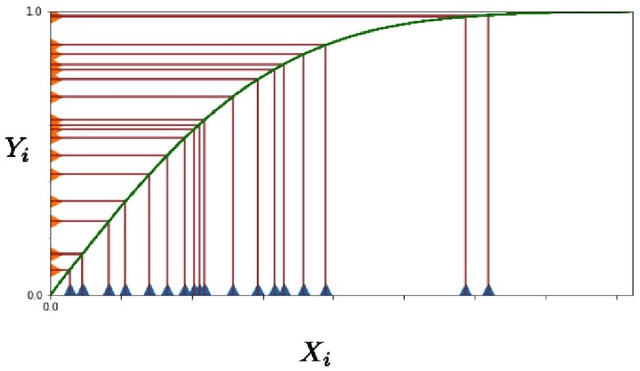
Understanding the shape of a distribution of data is of interest to people in a great variety of fields, as it may affect the types of algorithms used for that data. Given samples from a distribution, we seek to understand how many elements appear infrequently, that is, to characterize the tail of the distribution. We develop an algorithm based on a careful bucketing scheme that distinguishes heavy-tailed distributions from non-heavy-tailed ones via a definition based on the hazard rate under some natural smoothness and ordering assumptions. We verify our theoretical results empirically.
Via