 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Automated Fact-checking across Topics: Similarity-driven Gradual Topic Learning for Claim Detection
Nov 08, 2024Selecting check-worthy claims for fact-checking is considered a crucial part of expediting the fact-checking process by filtering out and ranking the check-worthy claims for being validated among the impressive amount of claims could be found online. The check-worthy claim detection task, however, becomes more challenging when the model needs to deal with new topics that differ from those seen earlier. In this study, we propose a domain-adaptation framework for check-worthy claims detection across topics for the Arabic language to adopt a new topic, mimicking a real-life scenario of the daily emergence of events worldwide. We propose the Gradual Topic Learning (GTL) model, which builds an ability to learning gradually and emphasizes the check-worthy claims for the target topic during several stages of the learning process. In addition, we introduce the Similarity-driven Gradual Topic Learning (SGTL) model that synthesizes gradual learning with a similarity-based strategy for the target topic. Our experiments demonstrate the effectiveness of our proposed model, showing an overall tendency for improving performance over the state-of-the-art baseline across 11 out of the 14 topics under study.
Check-worthy Claim Detection across Topics for Automated Fact-checking
Dec 16, 2022An important component of an automated fact-checking system is the claim check-worthiness detection system, which ranks sentences by prioritising them based on their need to be checked. Despite a body of research tackling the task, previous research has overlooked the challenging nature of identifying check-worthy claims across different topics. In this paper, we assess and quantify the challenge of detecting check-worthy claims for new, unseen topics. After highlighting the problem, we propose the AraCWA model to mitigate the performance deterioration when detecting check-worthy claims across topics. The AraCWA model enables boosting the performance for new topics by incorporating two components for few-shot learning and data augmentation. Using a publicly available dataset of Arabic tweets consisting of 14 different topics, we demonstrate that our proposed data augmentation strategy achieves substantial improvements across topics overall, where the extent of the improvement varies across topics. Further, we analyse the semantic similarities between topics, suggesting that the similarity metric could be used as a proxy to determine the difficulty level of an unseen topic prior to undertaking the task of labelling the underlying sentences.
Automated Fact-Checking: A Survey
Sep 23, 2021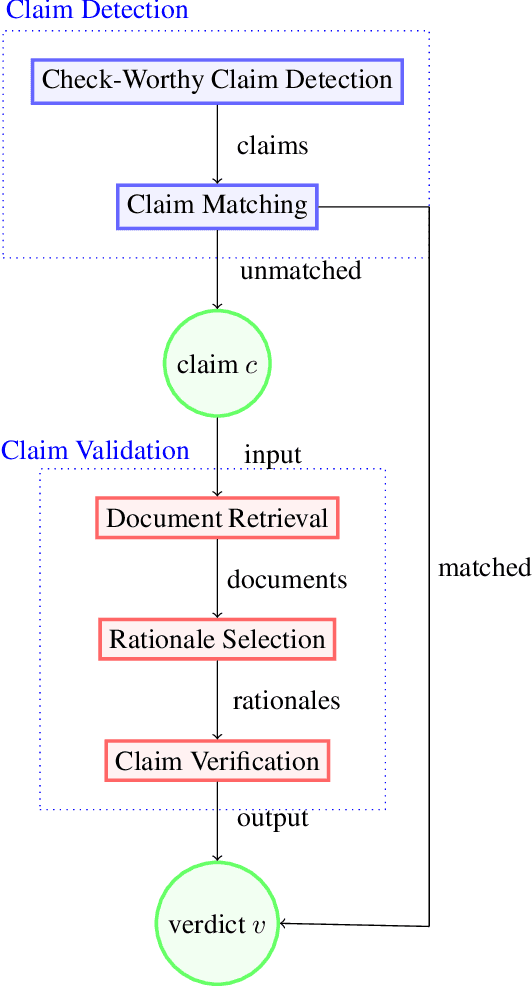
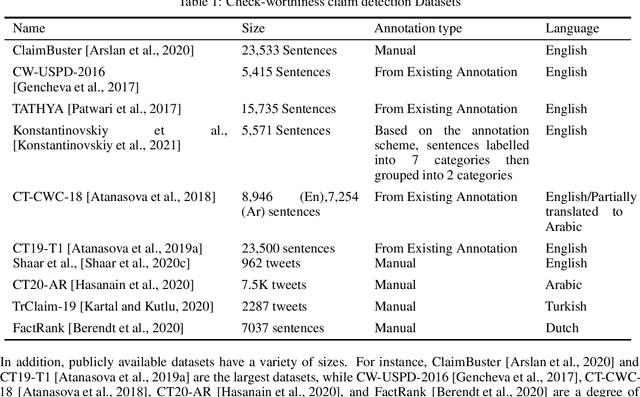
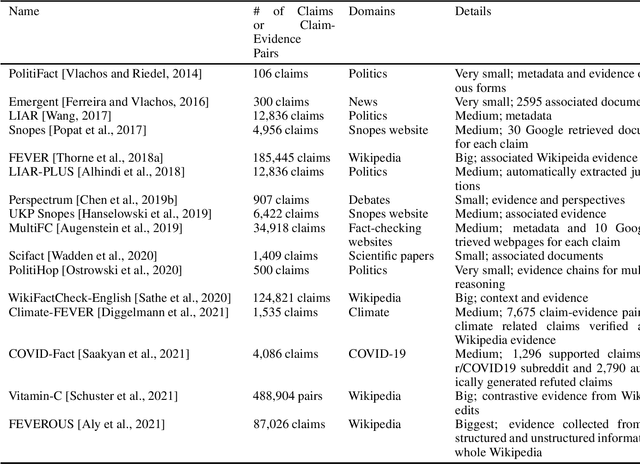
As online false information continues to grow, automated fact-checking has gained an increasing amount of attention in recent years. Researchers in the field of Natural Language Processing (NLP) have contributed to the task by building fact-checking datasets, devising automated fact-checking pipelines and proposing NLP methods to further research in the development of different components. This paper reviews relevant research on automated fact-checking covering both the claim detection and claim validation components.