 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-NLP team at SemEval-2020 Task 4: Evaluation of State-of-the-artNLP Deep Learning Architectures on Commonsense Reasoning Task
May 17, 2020
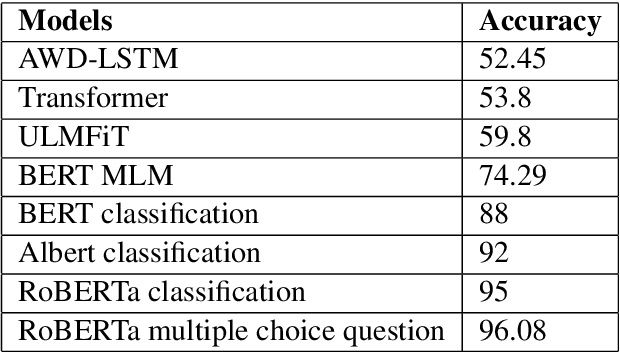

In this paper, we investigate a commonsense inference task that unifies natural language understanding and commonsense reasoning. We describe our attempt at SemEval-2020 Task 4competition: Commonsense Validation and Explanation (ComVE) challenge. We discuss several state-of-the-art deep learning architectures for this challenge. Our system uses prepared labeled textual datasets that were manually curated for three different natural language inference tasks.The goal of the first subtask is to test whether a model can distinguish between natural language statements that make sense and those that do not make sense. We compare the performance of several language models and fine-tuned classifiers. Then, we propose a method inspired by question/answering tasks to treat a classification problem as a multiple choice question task to boost the performance of our experimental results (96.06%), which is significantly better than the baseline. For the second subtask, which is to select the reason why a statement does not make sense, we stand within the first six teams (93.7%) among 27 participants with very competitive results.