 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent SHAP: Toward Practical Human-Interpretable Explanations
Nov 27, 2022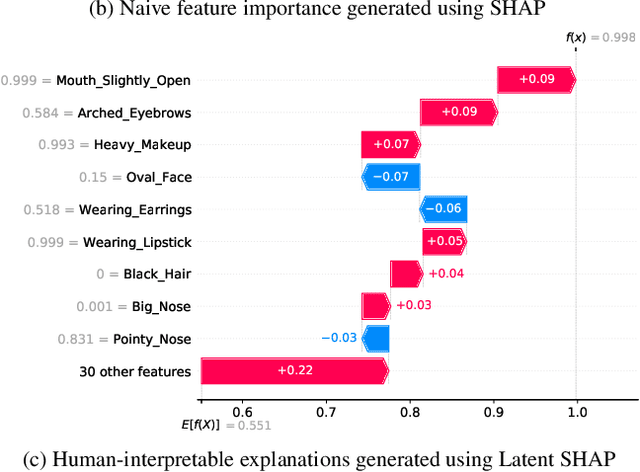
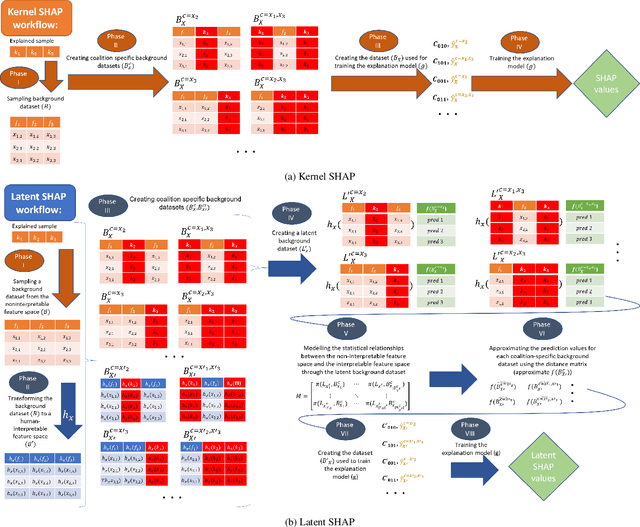
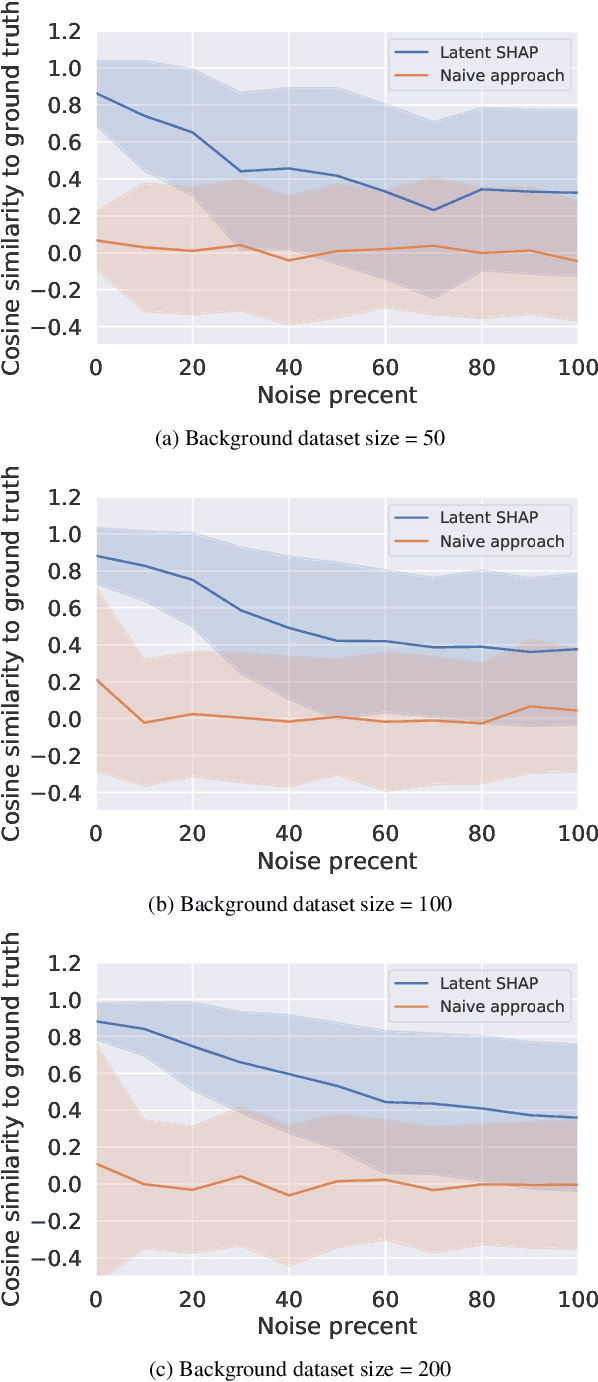
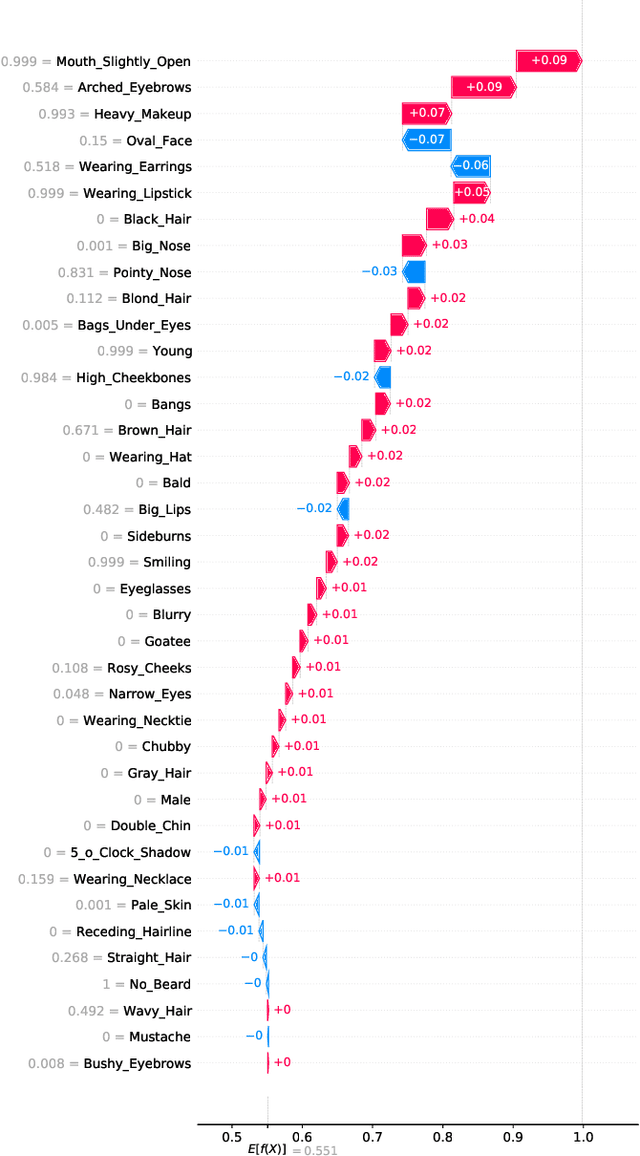
Model agnostic feature attribution algorithms (such as SHAP and LIME) are ubiquitous techniques for explaining the decisions of complex classification models, such as deep neural networks. However, since complex classification models produce superior performance when trained on low-level (or encoded) features, in many cases, the explanations generated by these algorithms are neither interpretable nor usable by humans. Methods proposed in recent studies that support the generation of human-interpretable explanations are impractical, because they require a fully invertible transformation function that maps the model's input features to the human-interpretable features. In this work, we introduce Latent SHAP, a black-box feature attribution framework that provides human-interpretable explanations, without the requirement for a fully invertible transformation function. We demonstrate Latent SHAP's effectiveness using (1) a controlled experiment where invertible transformation functions are available, which enables robust quantitative evaluation of our method, and (2) celebrity attractiveness classification (using the CelebA dataset) where invertible transformation functions are not available, which enables thorough qualitative evaluation of our method.